注意:由于结束部分的最后标签为”</p>”,而此标签在文章内容中多次出现。因此,不能作为采集规则的结束标签。考虑到应与文章内容的开始部分相对应,经对比和分析后得出,此处应选取“</div>”作为文章内容的结束部分,如图30所示,
图30-文章内容匹配规则的结束部分
(c)综合(a)和(b)可知,此处文章内容的匹配规则应为“<div class=”content”>[内容]</div>”,填写后,如图31所示,
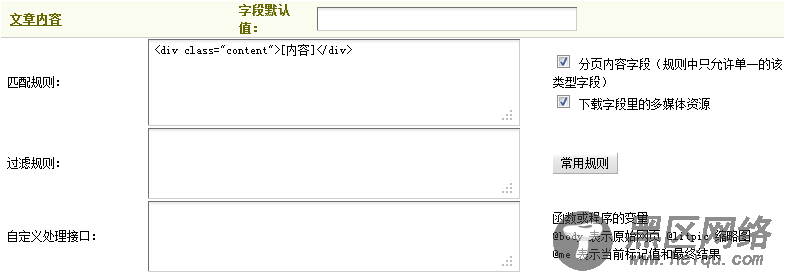
图31-文章内容的匹配规则
这里占时不使用过滤规则,关于过滤规则的介绍和使用,将会放在单独的章节中。
到这里,“新增采集节点:第二步设置内容字段获取规则”,就设置完成了。填写后,如(图32)所示,

图32-设置后的新增采集节点:第二步设置内容字段获取规则
检查无误后,单击“保存配置并预览”。如果之前设置正确,单击后,将会进入“新增采集节点:测试内容字段设置”页面并看到相应的文章内容。如(图33)所示,
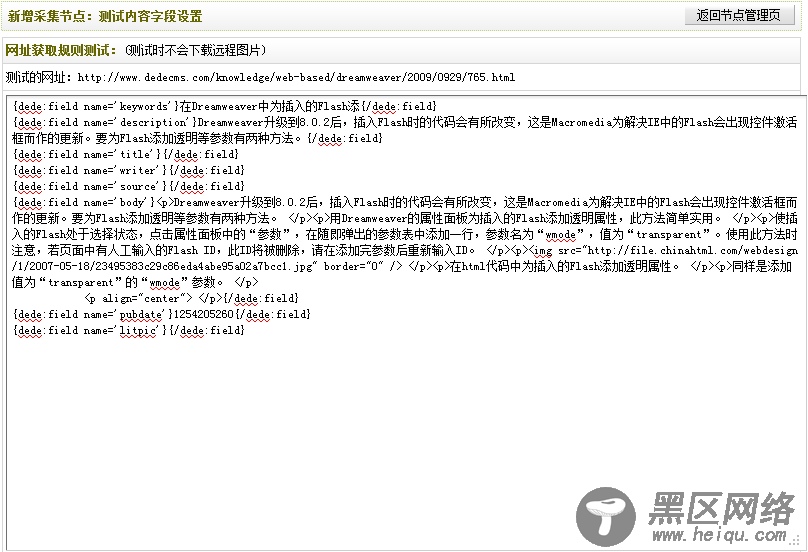
图33-新增采集节点:测试内容字段设置
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会进入”采集指定节点“界面。否则,请单击“返回上一步进行修改”。
关于第二节的介绍就到这里。下面进入第三节。。。