
/*
*
* 这段代码用来测试文件segment.fnm等文件所包含的内容
*
* */
生成的索引文件.fnm中所包含了Document的所有Field名称。
如图就是生成索引:
第一个截图是:
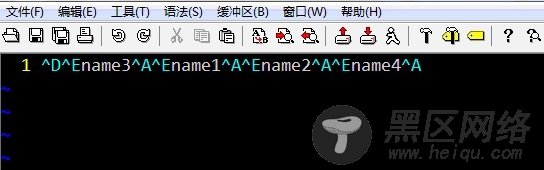
.fnm文件
.fnm包含了Document中的所有field名称
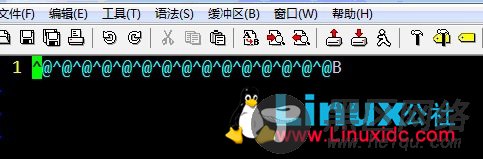
.fdx文件
.fd是一个是一个索引,用于存储Document在.fdt中的位置
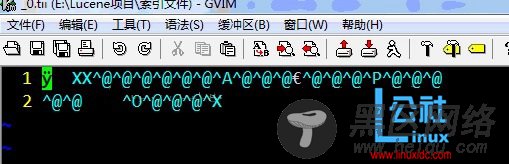
.fdt
.fdt文件用于存储具有Store.YES属性的Field数据

.tii
.tis文件用于存储分词后的词条(Term), 而.tii就是它的索引文件。
它标明了每个.tis文件中国的词条的位置
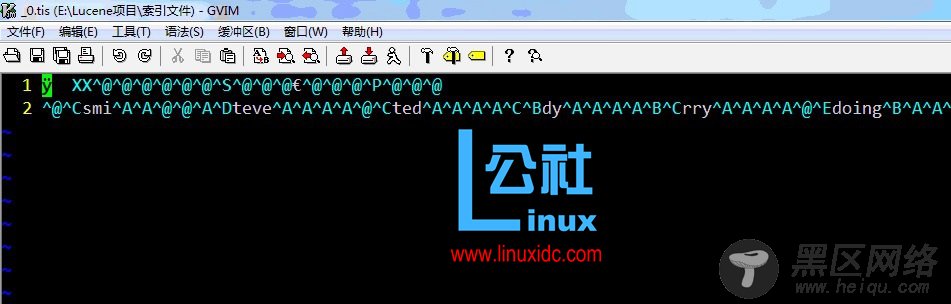
.tis
.tis文件用于存储分词后的词条(Term)
package segment;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
public class Segment {
private String INDEX_PATH = "E:\\Lucene项目\\索引文件";
Document doc1 = null;
Document doc2 = null;
public Segment(){
try
{ doc1 = new Document();
Field f1 = new Field("name1", "smi steve ted teddy terry", Field.Store.YES, Field.Index.TOKENIZED);
Field f2 = new Field("name2", "what are you doing", Field.Store.YES, Field.Index.TOKENIZED);
Field f3 = new Field("name3", "how do you do", Field.Store.YES, Field.Index.TOKENIZED);
doc1.add(f1);
doc1.add(f2);
doc1.add(f3);
doc2 = new Document();
Field f4 = new Field("name4", "smi steve ted teddy terry", Field.Store.YES, Field.Index.TOKENIZED);
Field f5 = new Field("name4", "what are you doing", Field.Store.YES, Field.Index.TOKENIZED);
doc2.add(f4);
doc2.add(f5);
IndexWriter writer = new IndexWriter(INDEX_PATH, new StandardAnalyzer(), true);
writer.setUseCompoundFile(false);
writer.addDocument(doc1);
writer.addDocument(doc2);
writer.close();
}catch(IOException e){
e.printStackTrace();
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
Segment se = new Segment();
}
}
--------------------------------------分割线 --------------------------------------
基于Lucene多索引进行索引和搜索 www.linuxidc.com/Linux/2012-05/59757.htm
Lucene + Hadoop 分布式搜索运行框架 Nut 1.0a9
Lucene + Hadoop 分布式搜索运行框架 Nut 1.0a8
Lucene + Hadoop 分布式搜索运行框架 Nut 1.0a7
Project 2-1: 配置Lucene, 建立WEB查询系统[Ubuntu 10.10]
--------------------------------------分割线 --------------------------------------