
也不清楚是设计的问题,还是实现的问题.
总之最后到我这里,是一个很奇怪的需求.
award_credit_room这个表,存放用户送礼的记录
award_credit 是用户送礼产生的积分记录
award_credit_room的数据经过汇总之后,需要批量Insert到award_credit表,
如果没有记录,则Insert,存在记录则Update
使用MySQL自定义变量,实现 insert..select...ON DUPLICATE KEY UPDATE
该功能使用如下SQL
set @a:=0;
set @b:=0;
insert into award_credit ( credits, vvid, CreditsTotal )
select @a:=sum(CreditChange) ,VVID,sum(CreditChange)
from award_credit_room r
where awardActId = 23 and Status = 2 group by VVID
ON DUPLICATE KEY UPDATE credits = credits + @a, creditsTotal = creditsTotal +@a;
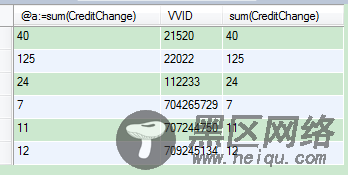
在执行之前的汇总查询结果
select @a:=sum(CreditChange) ,VVID,sum(CreditChange)
from award_credit_room r
where awardActId = 23 and Status = 2 group by VVID
在SQL执行之前的award_credit表数据
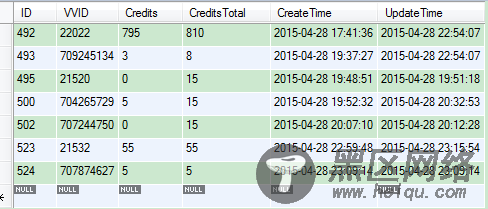
在SQL执行之后的award_credit表数据
在实验的过程中,有一个优化的想法,既然两个字段都是sum聚合,能不能使用自定义变量计算一次呢,
实际上是行不通的,自定义变量的执行顺序和变量的位置并不是严格固定的.
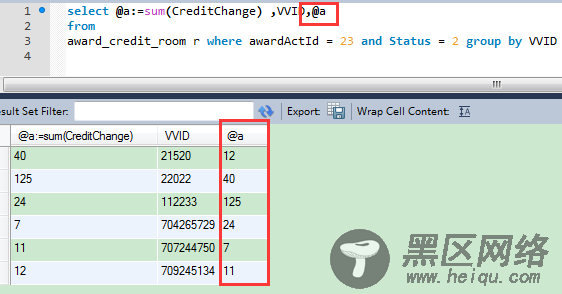
但是也有变通的方法
set @a:=0;
insert into award_credit ( credits, vvid, CreditsTotal )
select @a:=s,vvid,s from
(
select sum(CreditChange) s,VVID from award_credit_room r where awardActId = 23 and Status = 2 group by VVID
) t1
ON DUPLICATE KEY UPDATE credits = credits + @a, creditsTotal = creditsTotal +@a;