现在大多数开发用 react、vue、angular 来构建 SPA 网站, SPA 固有很多的优点, 比方开发速度快、模块化、组件化、性能优等。但其缺点还是很明显的, 首先就是首屏渲染问题, 其次不利于 SEO, 对爬虫不友好。
以 https://preview.pro.ant.design/#/dashboard/analysis 为例, 我们点击右键, 查看源代码, 发现其 body 里面只有 <div></div> ,假如想把门店销售额排名情况给爬下来,存到数据库进行数据分析(如下图)
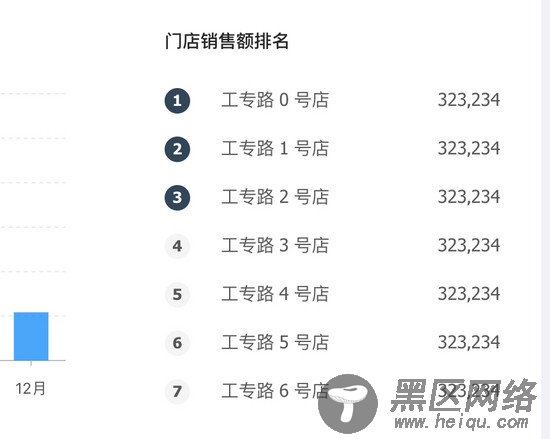
此时我们以传统爬虫的方式去爬的话是拿不到网页内容的。
如 python
# -*- coding : UTF-8 -*- from bs4 import BeautifulSoup import urllib2 def spider(): html = urllib2.urlopen('https://preview.pro.ant.design/#') html = html.read() soup = BeautifulSoup(html, 'lxml') print(soup.prettify()) if __name__ == '__main__': spider()
执行 python py/index.py , 得到的结果如下图:
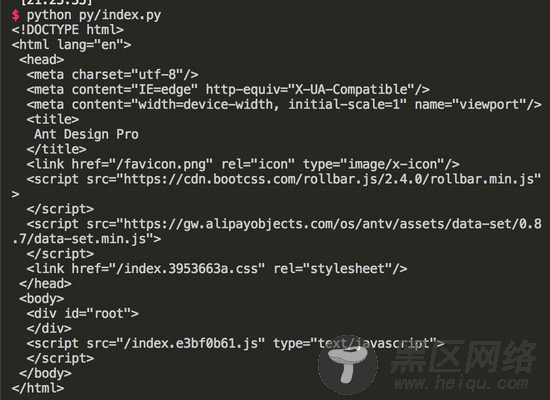
body 里面并没有页面相关的 dom,因此我们想通过 python 去爬取 SPA 页面的内容是不可行的。
nodejs
import axios from "axios"; (async () => { const res = await axios.get("https://preview.pro.ant.design/#"); console.log(res.data); })();
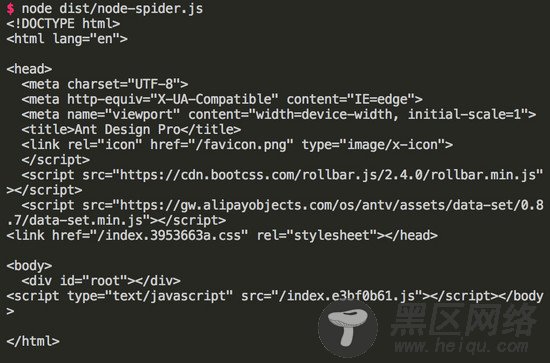
执行 node dist/node-spider.js , 得到和上面例子一样的结果。
puppeteer
(async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto("https://preview.pro.ant.design/#"); console.log(await page.content()); })();
执行 node dist/spider.js , 得到如下:

此时我们可以惊奇的发现可以抓到页面所有的 dom 节点了。此时我们可以把它保存下来做 SSR,也可以爬取我们想要的内容了。
(async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto("https://preview.pro.ant.design/#"); const RANK = ".rankingList___11Ilg li"; await page.waitForSelector(RANK); const res = await page.evaluate(() => { const getText = (v, selector) => { return v.querySelector(selector) && v.querySelector(selector).innerText; }; const salesRank = Array.from( document.querySelectorAll(".rankingList___11Ilg li") ); const data = []; salesRank.map(v => { const obj = { rank: getText(v, "span:nth-child(1)"), address: getText(v, "span:nth-child(2)"), sales: getText(v, "span:nth-child(3)") }; data.push(obj); }); return { data }; }); console.log(res); await browser.close(); })();
执行 node dist/spider.js , 得到如下:
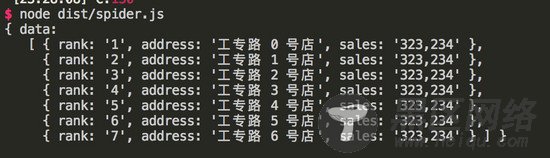
此时,我们已经利用 puppeteer 把我们所需要的数据给爬下来了。
到此,我们就把 puppeteer 基本的功能点给实现了一遍,本文示例代码可在 github 上获取。
参考