
基于MySQL Router可以实现高可用,读写分离,负载均衡之类的,MySQL Router可以说是非常轻量级的一个中间件了。
看了一下MySQL Router的原理,其实并不复杂,原理也并不难理解,其实就是一个类似于VIP的代理功能,其中一个MySQL Router有两个端口号,分别是对读和写的转发。
至于选择哪个端口号,需要在申请连接的时候自定义选择,换句话说就是在生成连接字符串的时候,要指明是读操作还是写操作,然后由MySQL Router转发到具体的服务器上。
引用这里的话说就是:
一般来说,通过不同端口实现读/写分离,并非好方法,最大的原因是需要在应用程序代码中指定这些连接端口。
但是,MySQL Router只能通过这种方式实现读写分离,所以MySQL Router拿来当玩具玩玩就好。其原理参考下图,相关安装配置等非常简单。
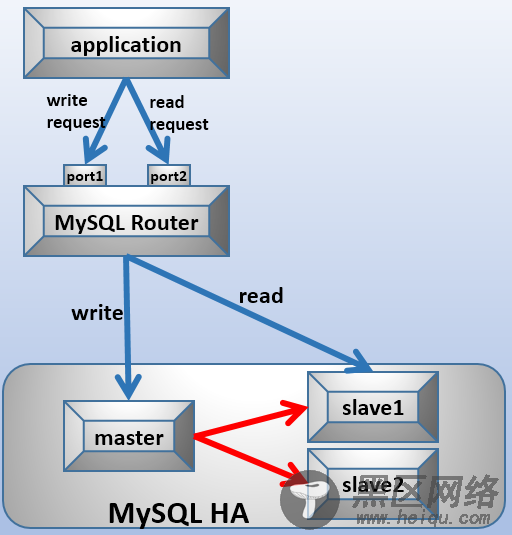
其实暂不论“MySQL Router拿来当玩具玩玩就好”,类似需要自己指定端口(或者说指定读写)来实现读写分离这种方式,自己完全可以实现,又何必用一个中间件呢?
对于MySQL Router来说,它自己本身又是单点的,还要考虑Router自身的高可用(解决了一个问题的同时又引入一个问题)。
很早之前就在想,可不可以尝试不借助中间件,也就无需关注中间件自身的高可用,自己实现读写分离呢?
对于最简单的master-salve复制的集群方式的读写分离,
可以基于在原始的数据库连接上指定一个优先级,把master服务器的优先级指定到最高,其余两个指定成一个较低的优先级
对于应用程序发起的请求,需要指明是读还是写,如果是写操作,就指定到master上执行,如果是读操作,就随机地指向slave操作,完全可以在连接层就实现类似于MySQL Router的功能。
其实非常简单,花不了多久就可以实现类似这么一个功能,在连接层实现读写分离,高可用,负载均衡,demo一个代码实现。
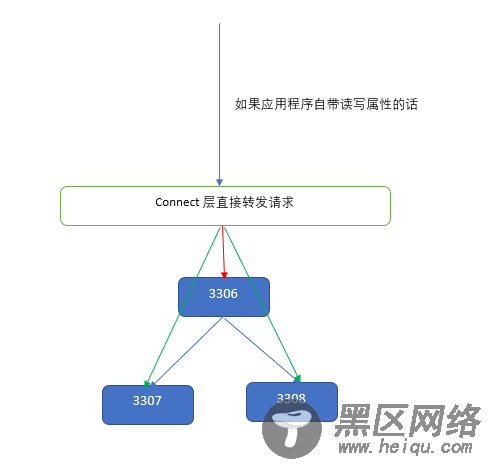
如下简单从数据库连接层实现了读写分离以及负载均衡。
1,写请求指向连接字符串中最高优先级的master,如果指定的最高优先级实例不可用,这里假如是实现了故障转移,依次寻找次优先级的实例
2,slave复制master的数据,读请求随机指向不同的slave,一旦某个slave不可用,继续寻找其他的slave
3,维护一个连接池,连接一律从连接池中获取。
故障转移可以独立实现,不需要在连接层做,连接层也不是做故障转移的。这样一旦发生故障,只要实现了故障转移,应用程序端可以不用做任何修改。
# -*- coding: utf-8 -*-
import pymysql
import random
from DBUtils.PooledDB import PooledDB
import socket
class MySQLRouter:
operation = None
conn_list = []
def __init__(self, *args, **kwargs):
for k, v in kwargs.items():
setattr(self, k, v)
# 探测实例端口号
@staticmethod
def get_mysqlservice_status(host,port):
mysql_stat = None
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
result = s.connect_ex((host, int(port)))
# port os open
if (result == 0):
mysql_stat = 1
return mysql_stat
def get_connection(self):
if not conn_list:
raise("no config error")
conn = None
current_conn = None
# 依据节点优先级排序
self.conn_list.sort(key=lambda k: (k.get('priority', 0)))
#写或者未定义请求,一律指向高优先级的服务器,可读写
if(self.operation.lower() == "write") or not self.operation:
for conn in conn_list:
# 如果最高优先级的主节点不可达,这里假设成功实现了故障转移,继续找次优先级的实例。
if self.get_mysqlservice_status(conn["host"], conn["port"]):
current_conn = conn
break
else:
continue
#读请求随机指向不同的slave
elif(self.operation.lower() == "read"):
#随机获取除了最该优先级节点之外的节点
conn_read_list = conn_list[1:len(conn_list)]
random.shuffle(conn_read_list)
for conn in conn_read_list:
#如果不可达,继续寻找其他除了主节点之外的节点
if self.get_mysqlservice_status(conn["host"], conn["port"]):
current_conn = conn
break
else:
continue
try:
#从连接池中获取当前连接
if (current_conn):
pool = PooledDB(pymysql,20, host=current_conn["host"], port=current_conn["port"], user=current_conn["user"], password=current_conn["password"],db=current_conn["database"])
conn = pool.connection()
except:
raise
if not conn:
raise("create connection error")
return conn;
if __name__ == '__main__':