
单位准备新上线一些功能,这些功能和原来生产库模块的功能是没有关系的,准备新建一个数据库给它使用。
但是他需要关联查询原来生产库的某些表。
后来的方案就是新建一个库,从原来的生产库复制需要的那几个表过来用于关联查询。
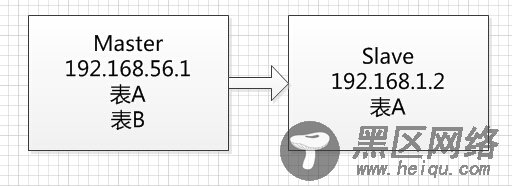
模拟如下
Master模拟生产库,Slave是新建的数据库,只是从Master服务器复制表A。
1.Master初始化数据,模拟线上运行一段时间的数据库
create database mvbox;
use mvbox;
create table a as select * from MySQL.user;
create table b as select * from mysql.db;
2.Master创建复制帐号
grant replication slave,replication client on *.*
to xx@'%' identified by 'xx';
3.修改Slave的配置文件
replicate-do-table=mvbox.a
4.Slave创建目标数据库 mvbox
create database mvbox;
5.Slave配置复制信息
change master to
master_host='192.168.56.1',
master_port=3306,
master_user='xx',
master_password='xx';
6.Slave导入Master的数据(Slave服务器上执行)
mysqldump -uxx -pxx -h192.168.56.1 --single-transaction --master-data mvbox a | mysql -uroot -Dmvbox
原理:
这个过程执行之前,查看Master的binlog位置
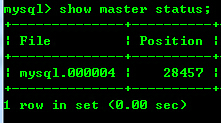
假如在Slave上生成Master SQL文件的内容
mysqldump -uxx -pxx -h192.168.56.1 --single-transaction --master-data mvbox a > a.sql
可以看到生成的内容已经包括了Master服务器binlog的信息
应用了mysqldump的内容之后
此时查看Slave的复制状态
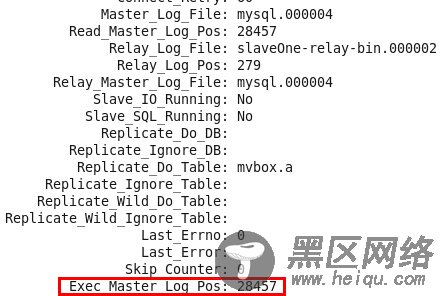
7.在Slave上启动复制
start slave;
--------------------------------------分割线 --------------------------------------
Ubuntu 14.04下安装MySQL
Ubuntu 14.04 LTS 安装 LNMP Nginx\PHP5 (PHP-FPM)\MySQL
Ubuntu 12.04 LTS 构建高可用分布式 MySQL 集群
Ubuntu 12.04下源代码安装MySQL5.6以及Python-MySQLdb
--------------------------------------分割线 --------------------------------------