
export HADOOP_HOME="/usr/local/hadoop"
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
运行以下命令以启动Yarn:
$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
我们可以通过以下命令来验证是否可以正确启动:
$ yarn node -list
2018-08-15 04:40:26,688 INFO client.RMProxy: Connecting to ResourceManager at hadoop1.admintome.lab/192.168.1.35:8032
Total Nodes:2
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop3.admintome.lab:35337 RUNNING hadoop3.admintome.lab:8042 0
hadoop2.admintome.lab:38135 RUNNING hadoop2.admintome.lab:8042 0
没有任何正在运行的容器,因为我们还没有开始任何工作。
Hadoop Web UI
我们可以通过以下URL来查看Hadoop Web UI:
:8088/cluster
替换Hadoop Master主机名:
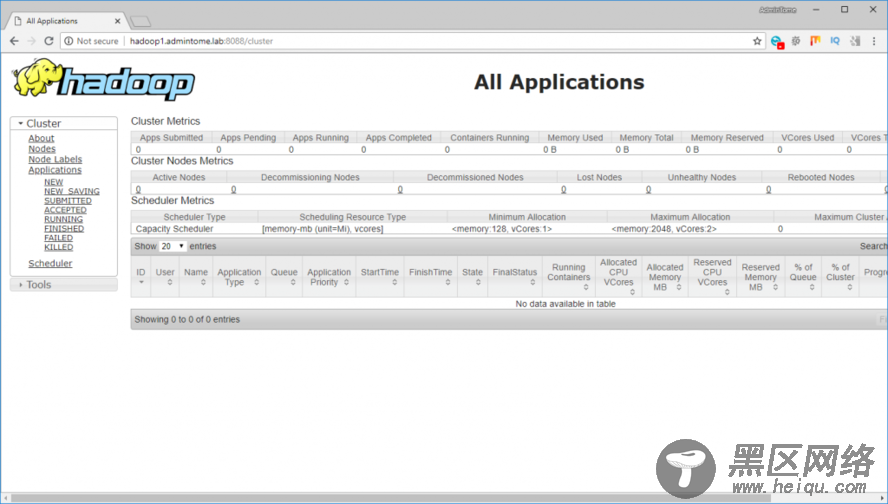
运行Hadoop任务示例
我们现在可以运行Hadoop任务示例并在集群上安排它,我们将运行的示例是使用MapReduce来计算PI。
运行以下命令来运行作业:
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar pi 16 1000
完成整个过程将需要几分钟的时间。完成后,应该可以看到它已经开始计算PI:
Job Finished in 72.973 seconds
Estimated value of Pi is 3.1425000000000000000