
前言:本文是“含有分页的普通文章的采集方法“的第二节,在前一节的基础上,这一节会对新增采集节点中的第二步:“设置字段获取规则”做详细的介绍。为了与前文保持一致,本文将延续使用前文的章节标记。
上接第一节。
2.1新增采集节点:第二步设置内容字段获取规则
单击“保存信息并进入下一步设置”后,便可进入“新增采集节点:第二步设置内容字段获取规则”页面,如(图14)所示,

图14-设置内容字段获取规则
系统将会自动指定一个“预览网址”,一般是文章列表页的第一篇文章的网址。但是,由于第一篇文章中没有涉及到分页的部分,所以在这里手动更改为,第二篇文章的网址:“”,更改后,如(图15)所示,

图15-更改后的预览地址
下面来设定分页部分的匹配规则。其具体操作步骤为:
打开文章内容页面,在网页上单击右键,在弹出的对话框中单击“查看源文件“。在源代码中,找到分页代码的开始部分和结束部分,如(图16)所示,

图16-分页代码
经过观察可知,分页代码位于“<div class=”page next-page”>“和”</div>”之间。因此,在”内容分页导航所在的区域匹配规则“中,应填写”<div class=”page next-page”>[内容]</div> “。对于分页代码的样式,一共有三种可供选择,这里应选择第一种” 全部列出的分页列表”。填写后,如(图17)所示,

图17-设置后的网页内容获取规则
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部分,系统会用正则进行自动匹配,这里仅需配置过滤内容即可。下面主要介绍如何获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
2.1.1 获取文章标题的采集规则首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题” OpenFlow网络是空谈吗?“,如(图18)所示,

图18-在源代码中的文章标题
这里的文章标题处在”<h1 class=“title”></h1>”之间,因此这里应该填写”<h1 class=“title”>[内容]</h1>”作为文章标题的匹配规则。如果在文章标题中含有相关链接等,可使用过滤规则加以处理,这里无需设置。填写后,如(图19)所示,
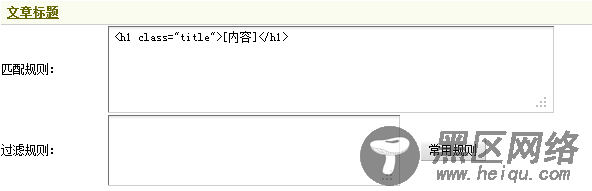
图19-文章标题的采集规则
2.1.2 获取文章作者的采集规则经过查找源代码和对比原文的标题部分,可发现本文没有涉及到文章作者,所以这里不用填写,空着即可。
2.1.3 获取文章来源的采集规则在上图19中,可发现来源的内容介于“<span>来源:“和“</span>”之间,因此这里应填写“<span>来源:[内容]</span>”作为文章来源的采集规则。同样,这里也不需要使用过滤规则。填写后,如图20所示,
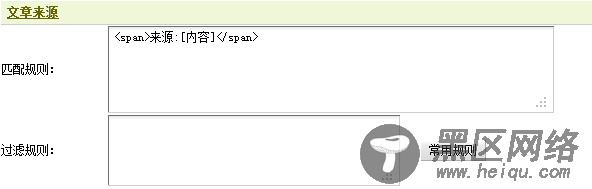
图20-文章来源的采集规则
2.1.4 获取文章发布时间的采集规则再次回到图17,可找到“时间:2011-05-13 11:47”,因此这里应把“时间:[内容]<span>”作为发布时间的采集规则。同样,这里也不需要使用过滤规则。填写后,如图21所示,
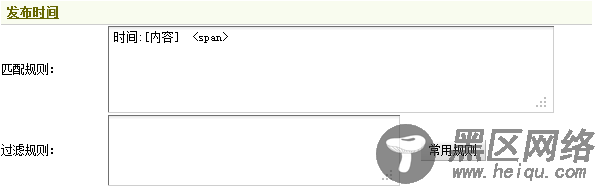
图21-文章发布时间的采集规则
2.1.5 获取文章内容的采集规则这个部分是编写采集规则的重点,也是难点。需要特别注意。
具体操作步骤:
(a)在在打开的文章内容页面的源代码中,找到文章内容的开始部分“计算机网络知识的学习”,如图22所示,

图22-文章内容的开始部分
这里应把”<!—文章块开始—>”作为匹配规则的开始部分,注意到这段代码中包含一段广告代码,需要采用过滤规则把其去除。经观察发现,这段JS广告代码是位于“<div class=”contentgg”>”和“</div>”之间的。因此,应在“过滤规则”中填写:“{dede:trim replace=’’}<div class=”contentgg”>(.*)</div>”{/dede:trim}。填写后,如(图23)所示,
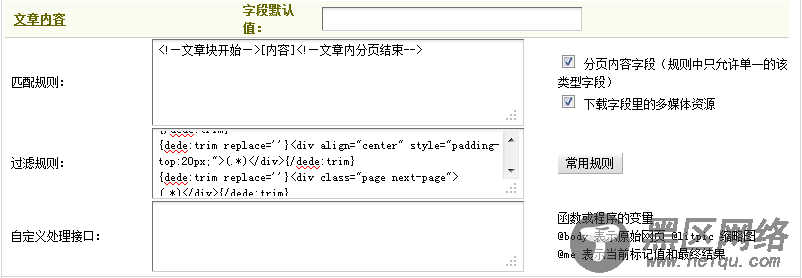
图23-开始部分的匹配规则及其过滤规则
(b)找到文章内容的结束部分,因为涉及到分页部分,所以应该选取分页结束的位置,如图24所示,

图24-文章内容的结束部分