Hadoop 的编程模型
Google 引用 MapReduce 的概念作为处理或生成大型数据集的编程模型。在规范模型中,map 函数处理键值对,这将得出键值对的中间集。然后 reduce 函数会处理这些中间键值对,并合并相关键的值(请参考图 1)。输入数据使用这样一种方法进行分区,即在并行处理的计算机集群中分区的方法。使用相同的方法,已生成的中间数据将被并行处理,这是处理大量数据的理想方法。
图 1. MapReduce 处理的简化视图
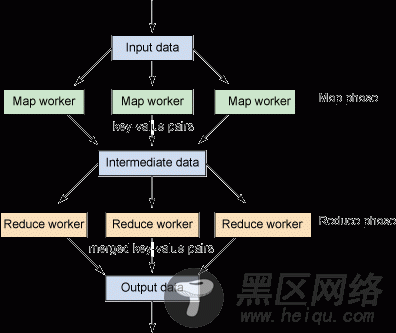
对于快速刷新器来说,查看图 1 的体系结构,从 map 和 reduce 角度来进行字数统计(因为您将在本文中开发 map 和 reduce 应用程序)。在提供输入数据时(进入 Hadoop 文件系统 [HDFS]),首先分段,然后分配给 map 工作线程(通过作业跟踪器)。虽然 图 2 中的示例显示了一个被分段的简短语句,但是分段的工作数量通常在 128MB 范围内,其原因是建立工作只需要很少的时间,因为有更多的工作要做,以便最大限度地减少这种开销。map 工作线程(在规范的示例中)将工作分割成包含已标记单词和初始值(在此情况下是 1)的单个矢量。在 map 任务完成时(如通过任务跟踪器在 Hadoop 中所定义的),提供工作给 reduce 工作线程。通过代表所发现的键的数量的值,reduce 工作线程将许多键缩减为一个惟一的集合。
图 2. 简单的 MapReduce 示例

请注意此过程可在相同的或不同的计算机中出现或者使用不同的数据分区来按顺序或并行完成,且结果仍然是相同的。
虽然规范的视图(用于使用字数统计生成搜索索引)是一种用来查看 Hadoop 方法,但结果是此计算模型被常规地应用到可计算问题上,正如您将要看到的那样。