
IN 和 EXISTS 是 SQL 中常见的复杂条件,在将 SQL(存储过程)转换成库外计算获取高性能时也会面对这些问题。本文将以 TPC-H 定义的模型为基础,介绍如何用集算器的语法实现 IN、EXISTS 并做优化。
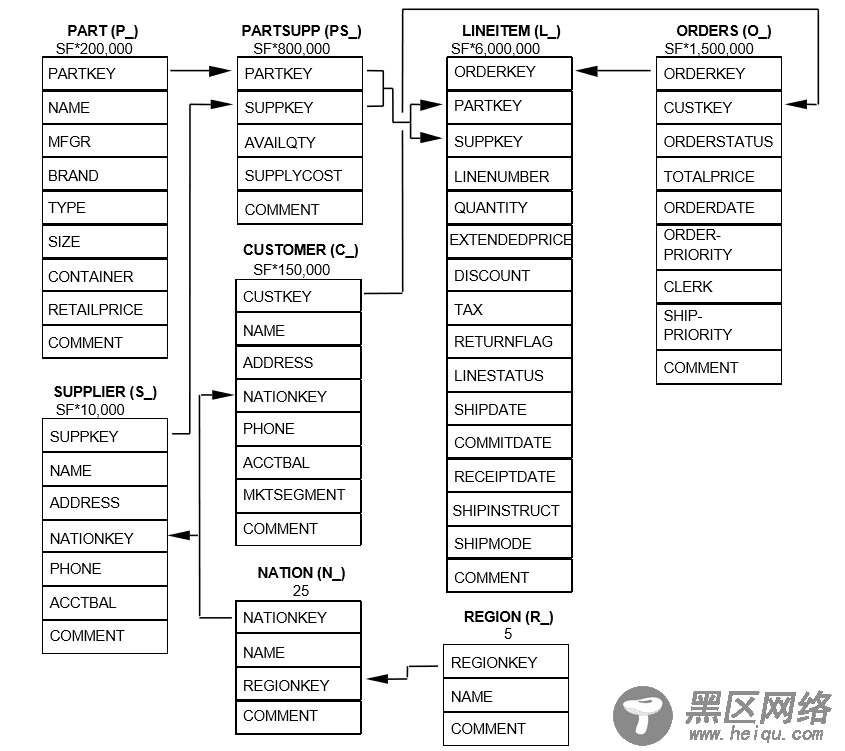
TPC-H 是 TPC 事务处理性能委员会制定的用于 OLAP 数据库管理系统的测试标准,模拟真实商业应用环境,以评估商业分析中决策支持系统的性能。TPC-H 模型定义了 8 张表,表结构和表关系如下图:
SQL 示例(1):
select
P_SIZE, P_TYPE, P_BRAND, count(1) as P_COUNT
from
PART
where
P_SIZE in (2, 3, 8, 15, 17, 25, 27, 28, 30, 38, 41, 44, 45)
and P_TYPE in ('SMALL BRUSHED NICKEL', 'SMALL POLISHED STEEL')
and P_BRAND not in ('Brand#12', 'Brand#13')
group by
P_SIZE, P_TYPE, P_BRAND
优化思路:
如果常数集合元素数少于 3 个则可以翻译成 (f == v1 || f == v2) 这种样式,NOT IN 对应的就是(f != v1 && f != v2)。较多的时候可以在外层把常数集合定义成序列,然后用 A.contain(f)来判断字段是否在序列中,经验表明元素个数超过 10 个时二分查找会明显快于顺序查找,如果要用二分查找则需要先把序列排序,然后用 A.contain@b(f)来进行有序查找,NOT IN 对应的就是! A.contain(f)。注意一定要把序列定义在循环函数外,否则会被多次执行。
如果常数集合元素数量特别多可以用连接过滤,具体请参照下图代码。
集算器实现:

如果 A1 的元素数量特别多,则可以使用哈希连接的方法来过滤,把第 3 行代码替换如下:

子查询选出字段是主键
SQL 示例(2):
select
PS_SUPPKEY, count(1) as S_COUNT
from
PARTSUPP
where
PS_PARTKEY in (
select
P_PARTKEY
from
PART
where
P_NAME like 'bisque%%'
)
group by
PS_SUPPKEY
优化思路:
子查询过滤后读入内存,然后外层表与先读入的内存表(子查询)做哈希连接进行过滤。集算器提供了 switch@i()、join@i() 两个函数用来做哈希连接过滤,switch 是外键式连接,用来把外键字段变成指引字段,这样就可以通过外键字段直接引用指向表的字段,join 函数不会改变外键字段的值,可用于只过滤。
集算器实现:

子查询选出字段不是主键
SQL 示例(3):
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and O_ORDERKEY in (
select
L_ORDERKEY
from
LINEITEM
where
L_COMMITDATE< L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
优化思路:
子查询过滤后按关联字段去重读入内存,然后就变成类似于主键的情况了,可以继续用上面说的 switch@i()、join@i() 两个函数用来做哈希连接过滤。
集算器实现:

子查询结果集存放不下
SQL 示例(3):
select
O_ORDERPRIORITY, count(*) as O_COUNT
from
ORDERS
where
O_ORDERDATE >= date '1995-10-01'
and O_ORDERDATE < date '1995-10-01' + interval '3' month
and O_ORDERKEY in (
select
L_ORDERKEY
from
LINEITEM
where
L_COMMITDATE< L_RECEIPTDATE
)
group by
O_ORDERPRIORITY
优化思路:
IN 子查询相当于对子查询结果集去重然后跟外层表做内连接,而做连接效率较好的就是哈希连接和有序归并连接,所以这个问题就变成了怎么把 IN 翻译成高效的连接,下面我们来分析在不同的数据分布下如何把 IN 转成连接。
(1) 外层表数据量比较小可以装入内存:
先读入外层表,如果外层表关联字段不是逻辑主键则去重,再拿上一步算出来的关联字段的值对子查询做哈希连接过滤,最后拿算出来的子查询关联字段的值对外层表做哈希连接过滤。
(2) 外层表和内层表按关联字段有序:
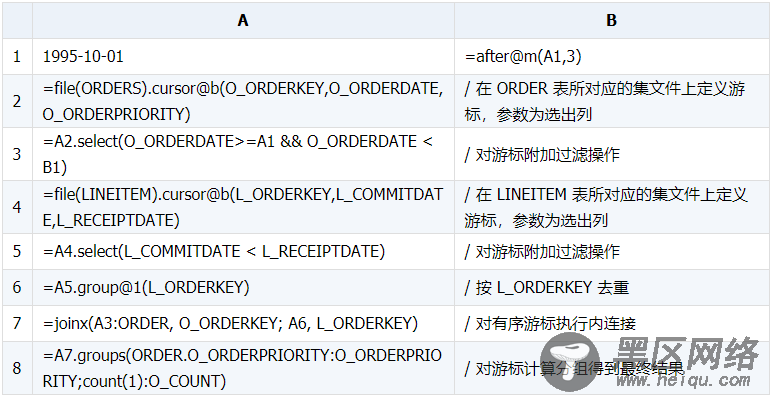
此时可以利用函数 joinx() 来做有序游标的归并连接,如果内层表关联字段不是逻辑主键则需要先去重。此例中的 ORDERS 表和 LINEITEM 表是按照 ORDERKEY 同序存放,可以利用此方法来做优化。
(3) 内层表是大维表并且按主键有序存放:
集算器提供了针对有序大维表文件做连接的函数 A.joinx,其它方法跟内存能放下时的处理类似在此不再描述。
集算器实现(1):

集算器实现(2):
此章节的优化思路和 IN 子查询的优化思路是相同的,事实上这种 EXISTS 也都可以用 IN 写出来(或者倒过来,把 IN 用 EXISTS 写出来)。
子查询关联字段是主键
SQL 示例(4):
select
PS_SUPPKEY, count(1) as S_COUNT
from
PARTSUPP
where
exists (
select
*
from
PART
where
P_PARTKEY = PS_PARTKEY
and P_NAME like 'bisque%%'
)
group by
PS_SUPPKEY
优化思路: