
我们在Hadoop配置集群时,经常将namenode与secondarynamenode存放在一个节点上,其实这是非常危险的,如果此节点崩溃的话,则整个集群不可恢复。下面介绍一下将namenode与secondarynamenode分离的方法。当然还存在好多不足和待改进的地方,欢迎各位大神指点和吐槽。
非常说明:我原本以为masters配置文件中的内容(主机名)是指的namenode的主机名称,但它实际上指的是secondarynamenode,slavers配置文件指的是运行了 datanode 和 tasktracker(一般是同一节点)的所有节点。并且这两个文件只有在运行namenode和jobtracker(一般都在namenode节点上 namenode由core-site.xml fs.default.name指定,jobtracker由mapred-site.xml mapred.job.tracker指定)的节点才被用到,所以其它节点可以不进行配置。
所以千万不要忘记修改namenode节点中masters文件中的内容
言归正传(本实验结合本文中的集群搭建后的环境进行的)
1 将namenode所在的节点进行克隆,即新建一个节点,包括conf目录下的文件配置
所有文件、目录结构、环境变量等都要相同。可参考给集群添加一个新建节点一节,相关配置如:
主机名 secondary
IP 192.168.5.16
hosts文件 :
192.168.5.13 namenode
192.168.5.16 secondary
SSH免密码登录
关于hosts文件和ssh,我认为secondarynamenode只与namenode通信,所以只需跟namenode节点建立无密码连接即可,并且hosts文件的内容可以只写namenode节点和自身的信息,注意namenode节点中的hosts文件也需添加secondarynamenode节点的信息才可。
2 文件配置
(1)在namenode节点中 修改hdfs-site.xml文件为:
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.5.16:50090</value>
<description>NameNode get the newest fsimage via dfs.secondary.http.address </description>
</property>
在masters文件中修改为secondary
(2)在secondarynamenodenamenode节点中 修改hdfs-site.xml文件为:
<property>
<name>dfs.http.address</name>
<value>192.168.5.13:50070</value>
<description>Secondary get fsimage and edits via dfs.http.address</description>
</property>
修改core-site.xml文件
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
<description>The number of seconds between two periodic checkpoints.</description>
</property>
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/home/zhang/hadoop0202/secondaryname</value>
</property>
其中fs.checkpoint.period和fs.checkpoint.size是SecondaryNameNode节点开始备份满足的条件,当满足两种情况中的任意一个,SecondaryNameNode节点都会开始备份,第一个为设定的间隔时间到了(默认为一小时)fs.checkpoint.period设置的时间(以秒为单位),第二个为操作日志文件的大小达到了fs.checkpoint.size中设置的阈值。
3 重启 hadoop或者在secondary上直接进行
hadoop-daemon.sh start secondarynamenode 命令启动secondaryNamenode
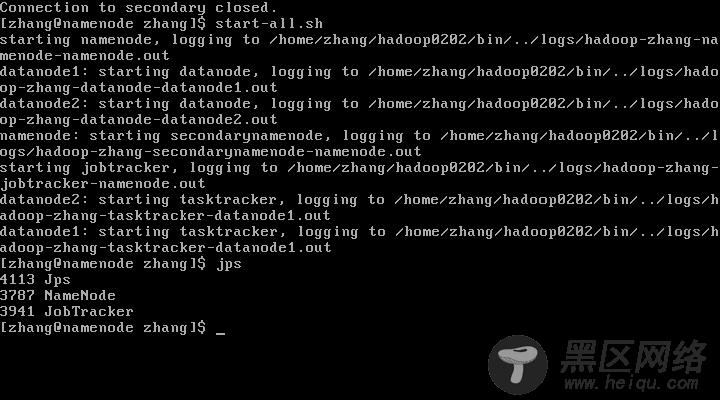
重启后我们可以看到
在namenode中没有了SecondaryNameNode的Java进程(很抱歉,忘记分离之前截图了,分离之前在namenode节点上确实有SecondaryNameNode的Java进程)
在secondary节点上出现SecondaryNameNode的Java进程

验证:在secondary节点上的secondaryname目录中是否有了有了镜像文件(由于在设置core-siet.xml文件中的fs.checkpoint.period参数是3600,代表一小时,我们为了实验效果要进行参数修改,修改效果可以参照《怎样控制namenode检查点的发生频率》一文 )
Ubuntu14.04下Hadoop2.4.1单机/伪分布式安装配置教程
CentOS安装和配置Hadoop2.2.0