
公司近期Storm清洗程序那边反应HDFS会出现偶发性的异常导致数据写不进HDFS,另外一些Spark作业在大规模往HDFS灌数据时客户端会出现各种“all datanode bad..”以及服务端出现各种timeout,值得注意的是出现这样的问题是各个datanode节点的负载并不高!
二、故障分析
首先,当我们在HDFS客户端看到各种timeOut...什么waiting for reading等信息的时候,我们第一反应是为什么在往HDFS写数据时组成pipeline的各个datanode接收不到上游datanode的packet?这时候往往有人会说增加什么与客户端的超时时间,这个是肯定不行的(因为各个节点的负载非常低)。另外,如果出现“All datanode bad..”这种错误,我们往往会最先蹦出2种想法,第一:所有datanode都无法提供服务了,第二:dfsClient与hdfs服务端的DataXServer线程连接但是长时间没有packet传输而导致hdfs服务端启动保护机制自动断开,最终导致。
对于现在“All datanode bad..”这种问题,我基本可以排除第二种情况。再往下看,在平台监控系统中观察datanode的Thread Dump信息以及心跳信息,发现问题了:
重现异常情况,观察所有datanode的Thread Dump和心跳情况:
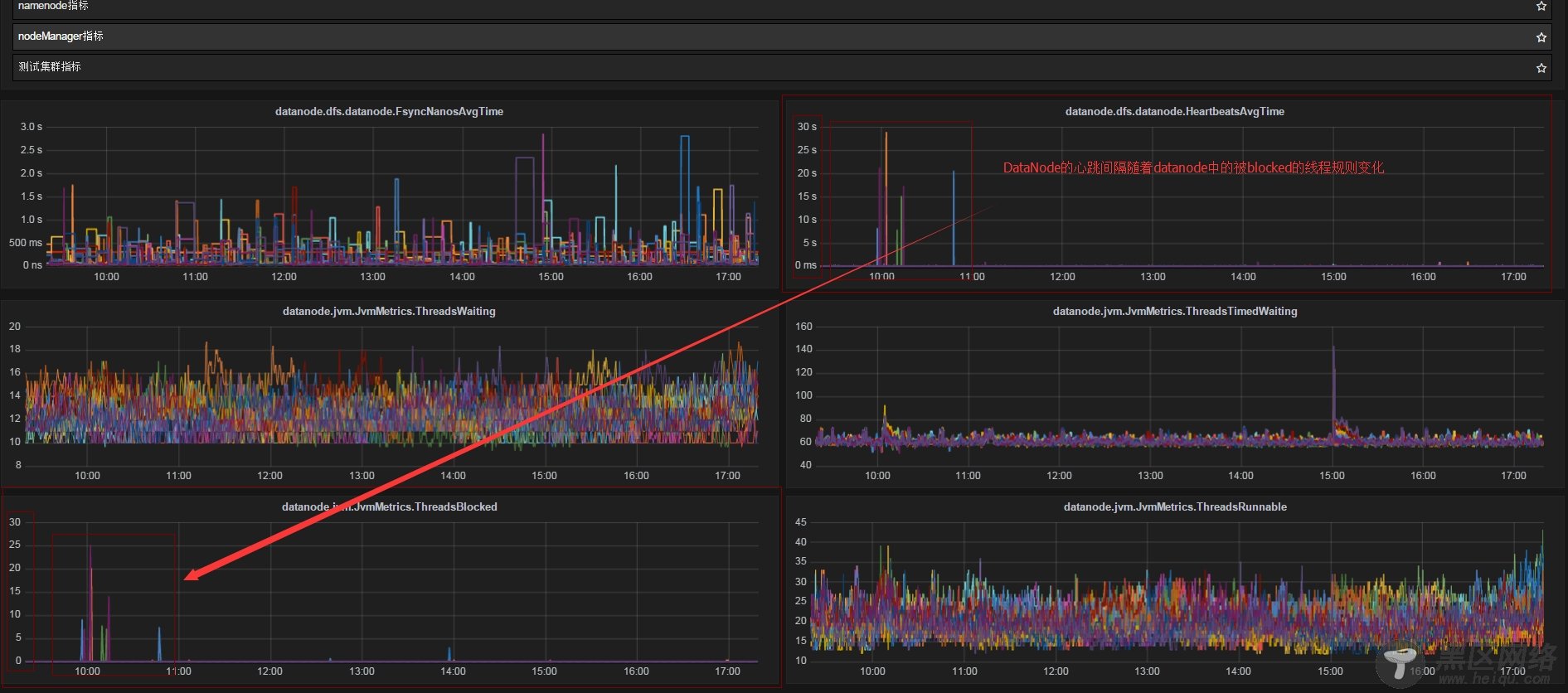
这个非常恐怖,心跳达到30s!!
更进一步分析,直接重现谷中,用jstack -l 命令看datanode具体的Thread Dump信息发现系统高密度调用FsDataSetImp中createTemporary和checkDirs方法:
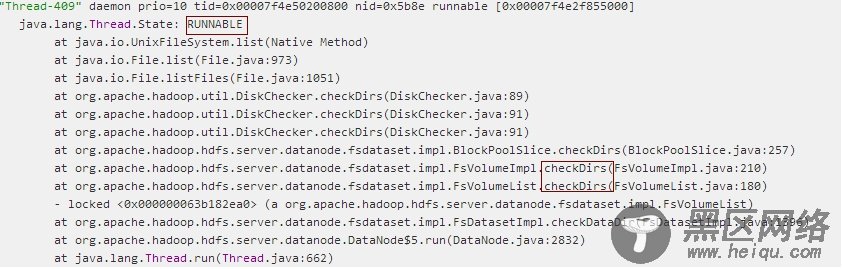
由于上面频发调用在粗粒度对象锁FsDatasetImpl作用下的方法,导致发送心跳以及DataXceiver线程被blocked掉(因为他们同样在粗粒度对象锁FsDatasetImpl作用下),看Thread Dump信息,DataNode处理请求的DataXceiver线程被blocked:
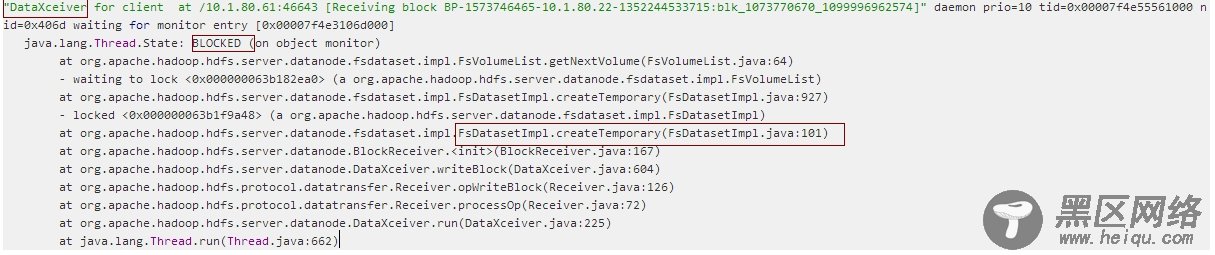
发送心跳线程被blocked掉:

对于发送心跳的线程被blocked掉,从源码的看来主要是由于datanode向namenode发送心跳需要获得所在节点的资源相关情况,心跳通过getDfUsed,getCapacity,getAvailable,getBlockPoolUsed等方法获得(看FsDatasetImpl代码):
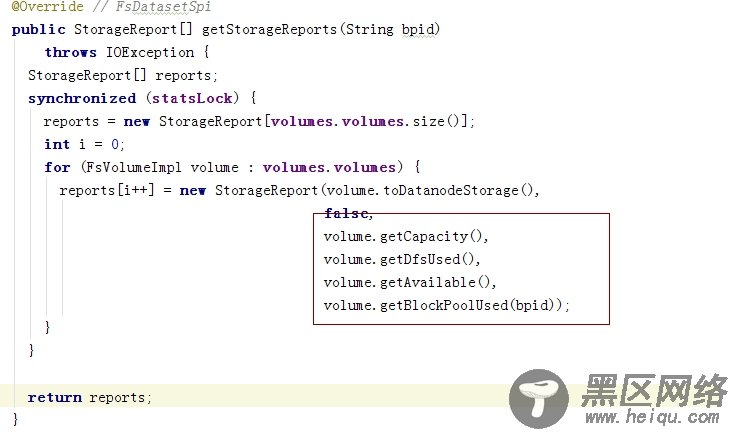
而这几个方法又是在FsDatasetImpl对象锁的作用范围下,因此心跳线程被blocked掉,具体看下getDfSUSEd源码:

通过上面一轮的分析,基本可以分析故障原因:大规模往hdfs同时写多批文件,Datanode Thread Dump大量DataXceiver和发送心跳线程被Blocked掉,出现心跳异常有时候达到几十秒左右,大量DataXceiver线程被blocked掉无法向各个dfsClient的dataStreamer(向datanode发送packet)和ResponseProcessor(接收pipeline中datanode的ack)线程提供服务和datanode的BlockReceiver线程无法正常工作,最终导致客户端出现timeOut,或者dfsClient往hdfs写packet时整个PipeLine中的datanode无法响应客户端请求,进而系统内部启动pipeline容错,但是各个datanode都由于DataXceiver大量被Blocked掉无法提供服务,最后导致客户端报出“All dataNode are bad....”和服务端的timoeut。
换句话来说这个是HDFS中的一个大BUG。
这个是Hadoop2.6中的bug,代码中采用了非常大粒度的对象锁(FsDatasetImpl),在大规模写操作时导致锁异常。这个bug出现在2.5和2.6这2个版本中(我们新集群用的是2.6),目前这个bug已经在2.6.1和2.7.0这2个版本中修复。官方具体给出的Patch信息:
https://issues.apache.org/jira/browse/HDFS-7489
https://issues.apache.org/jira/browse/HDFS-7999
其实具体的修复方案就是将这个大粒度的对象锁分解为多个小粒度的锁,并且将datande向namenode发送心跳线程从相关联的锁中剥离。
为了进一步确认,这是hadoop2.6中一个bug,我通过将测试集群升级到2.7.1(bug修复版本),对比2.7.1bug修复版本在大规模写多批文件时的datanode心跳线程以及DataXceiver线程的blocked以及心跳间隔情况。下面是hadoop2.7.1表现情况:
