
本文重点推荐Codis——豌豆荚开源的Redis分布式中间件(该项目于4个月前在GitHub开源,目前star已超过2100)。其和Twemproxy相比,有诸多激动人心的新特性,并支持从Twemproxy无缝迁移至Codis。
好吧我们正式开始。

长期以来,Redis本身仅支持单实例,内存一般最多10~20GB。这无法支撑大型线上业务系统的需求。而且也造成资源的利用率过低——毕竟现在服务器内存动辄100~200GB。
为解决单机承载能力不足的问题,各大互联网企业纷纷出手,“自助式”地实现了集群机制。在这些非官方集群解决方案中,物理上把数据“分片”(sharding)存储在多个Redis实例,一般情况下,每一“片”是一个Redis实例。
包括官方近期推出的Redis Cluster,Redis集群有三种实现机制,分别介绍如下,希望对大家选型有所帮助。
1.1 客户端分片这种方案将分片工作放在业务程序端,程序代码根据预先设置的路由规则,直接对多个Redis实例进行分布式访问。这样的好处是,不依赖于第三方分布式中间件,实现方法和代码都自己掌控,可随时调整,不用担心踩到坑。
这实际上是一种静态分片技术。Redis实例的增减,都得手工调整分片程序。基于此分片机制的开源产品,现在仍不多见。
这种分片机制的性能比代理式更好(少了一个中间分发环节)。但缺点是升级麻烦,对研发人员的个人依赖性强——需要有较强的程序开发能力做后盾。如果主力程序员离职,可能新的负责人,会选择重写一遍。
所以,这种方式下,可运维性较差。出现故障,定位和解决都得研发和运维配合着解决,故障时间变长。
这种方案,难以进行标准化运维,不太适合中小公司(除非有足够的DevOPS)。
1.2 代理分片这种方案,将分片工作交给专门的代理程序来做。代理程序接收到来自业务程序的数据请求,根据路由规则,将这些请求分发给正确的Redis实例并返回给业务程序。
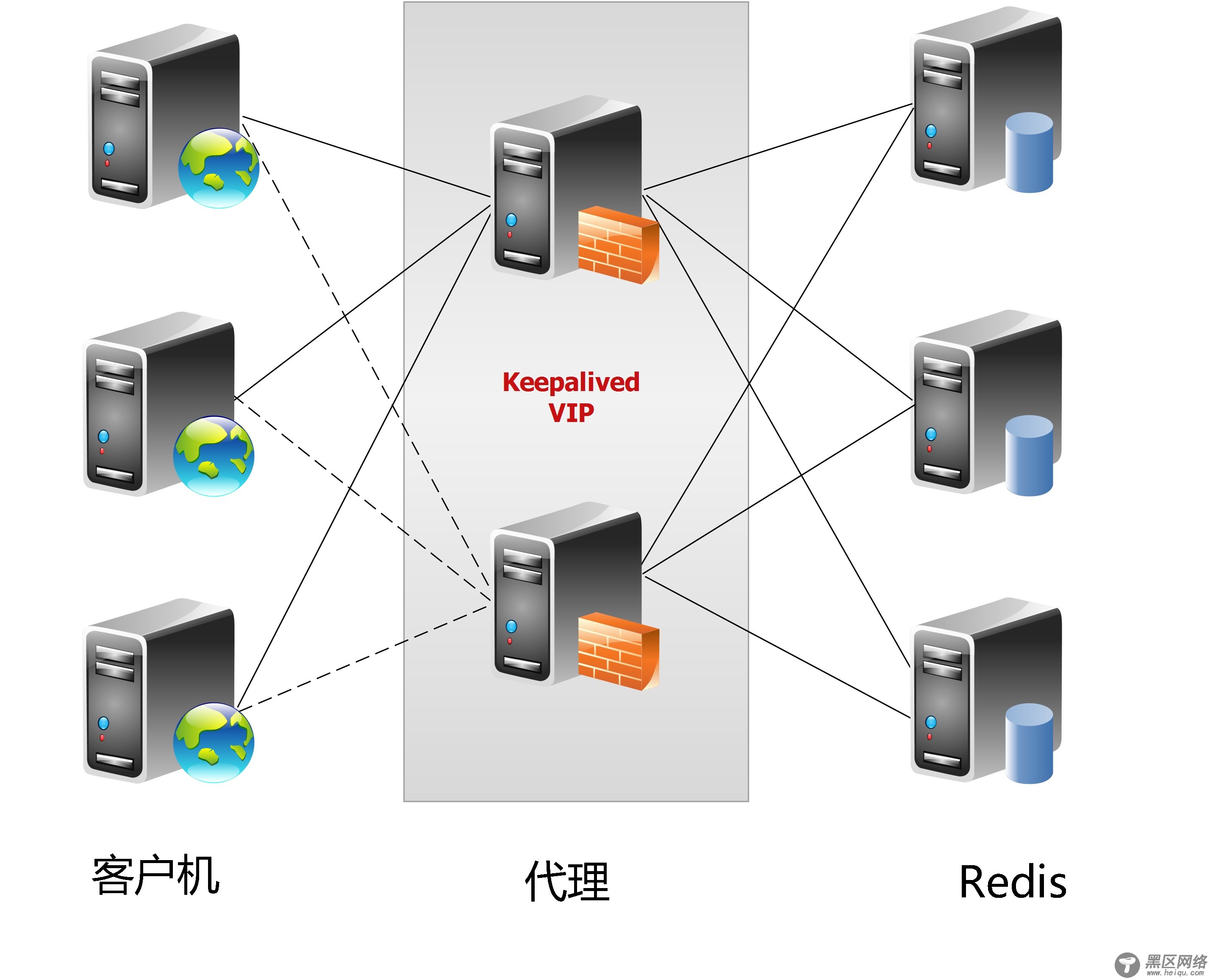
这种机制下,一般会选用第三方代理程序(而不是自己研发),因为后端有多个Redis实例,所以这类程序又称为分布式中间件。
这样的好处是,业务程序不用关心后端Redis实例,运维起来也方便。虽然会因此带来些性能损耗,但对于Redis这种内存读写型应用,相对而言是能容忍的。
这是我们推荐的集群实现方案。像基于该机制的开源产品Twemproxy,便是其中代表之一,应用非常广泛。
Ubuntu 14.04下Redis安装及简单测试
Redis集群明细文档
Ubuntu 12.10下安装Redis(图文详解)+ Jedis连接Redis
CentOS 6.3安装Redis
1.3 Redis Cluster在这种机制下,没有中心节点(和代理模式的重要不同之处)。所以,一切开心和不开心的事情,都将基于此而展开。
Redis Cluster将所有Key映射到16384个Slot中,集群中每个Redis实例负责一部分,业务程序通过集成的Redis Cluster客户端进行操作。客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。
Redis Cluster的成员管理(节点名称、IP、端口、状态、角色)等,都通过节点之间两两通讯,定期交换并更新。
由此可见,这是一种非常“重”的方案。已经不是Redis单实例的“简单、可依赖”了。可能这也是延期多年之后,才近期发布的原因之一。
这令人想起一段历史。因为Memcache不支持持久化,所以有人写了一个Membase,后来改名叫Couchbase,说是支持Auto Rebalance,好几年了,至今都没多少家公司在使用。
这是个令人忧心忡忡的方案。为解决仲裁等集群管理的问题,Oracle RAC还会使用存储设备的一块空间。而Redis Cluster,是一种完全的去中心化……
本方案目前不推荐使用,从了解的情况来看,线上业务的实际应用也并不多见。
2. Twemproxy及不足之处