
这么多的 FULL GC,应该是内存泄漏没跑了,于是 使用 jstack pid > jstack.log 保存了线程栈的现场,使用 jmap -dump:format=b,file=heap.log pid 保存了堆现场,然后重启了探测服务,报警邮件终于停止了。
jstatjstat 是一个非常强大的 JVM 监控工具,一般用法是: jstat [-options] pid interval
它支持的查看项有:
-class 查看类加载信息
-compile 编译统计信息
-gc 垃圾回收信息
-gcXXX 各区域 GC 的详细信息 如 -gcold
使用它,对定位 JVM 的内存问题很有帮助。
排查问题虽然解决了,但为了防止它再次发生,还是要把根源揪出来。
分析栈栈的分析很简单,看一下线程数是不是过多,多数栈都在干嘛。
>grep 'java.lang.Thread.State' jstack.log | wc -l > 464
才四百多线程,并无异常。
> grep -A 1 'java.lang.Thread.State' jstack.log | grep -v 'java.lang.Thread.State' | sort | uniq -c |sort -n 10 at java.lang.Class.forName0(Native Method) 10 at java.lang.Object.wait(Native Method) 16 at java.lang.ClassLoader.loadClass(ClassLoader.java:404) 44 at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method) 344 at sun.misc.Unsafe.park(Native Method)
线程状态好像也无异常,接下来分析堆文件。
下载堆 dump 文件。堆文件都是一些二进制数据,在命令行查看非常麻烦,Java 为我们提供的工具都是可视化的,Linux 服务器上又没法查看,那么首先要把文件下载到本地。
由于我们设置的堆内存为 4G,所以 dump 出来的堆文件也很大,下载它确实非常费事,不过我们可以先对它进行一次压缩。
gzip 是个功能很强大的压缩命令,特别是我们可以设置 -1 ~ -9 来指定它的压缩级别,数据越大压缩比率越大,耗时也就越长,推荐使用 -6~7, -9 实在是太慢了,且收益不大,有这个压缩的时间,多出来的文件也下载好了。
使用 MAT 分析 jvm heapMAT 是分析 Java 堆内存的利器,使用它打开我们的堆文件(将文件后缀改为 .hprof), 它会提示我们要分析的种类,对于这次分析,果断选择 memory leak suspect。
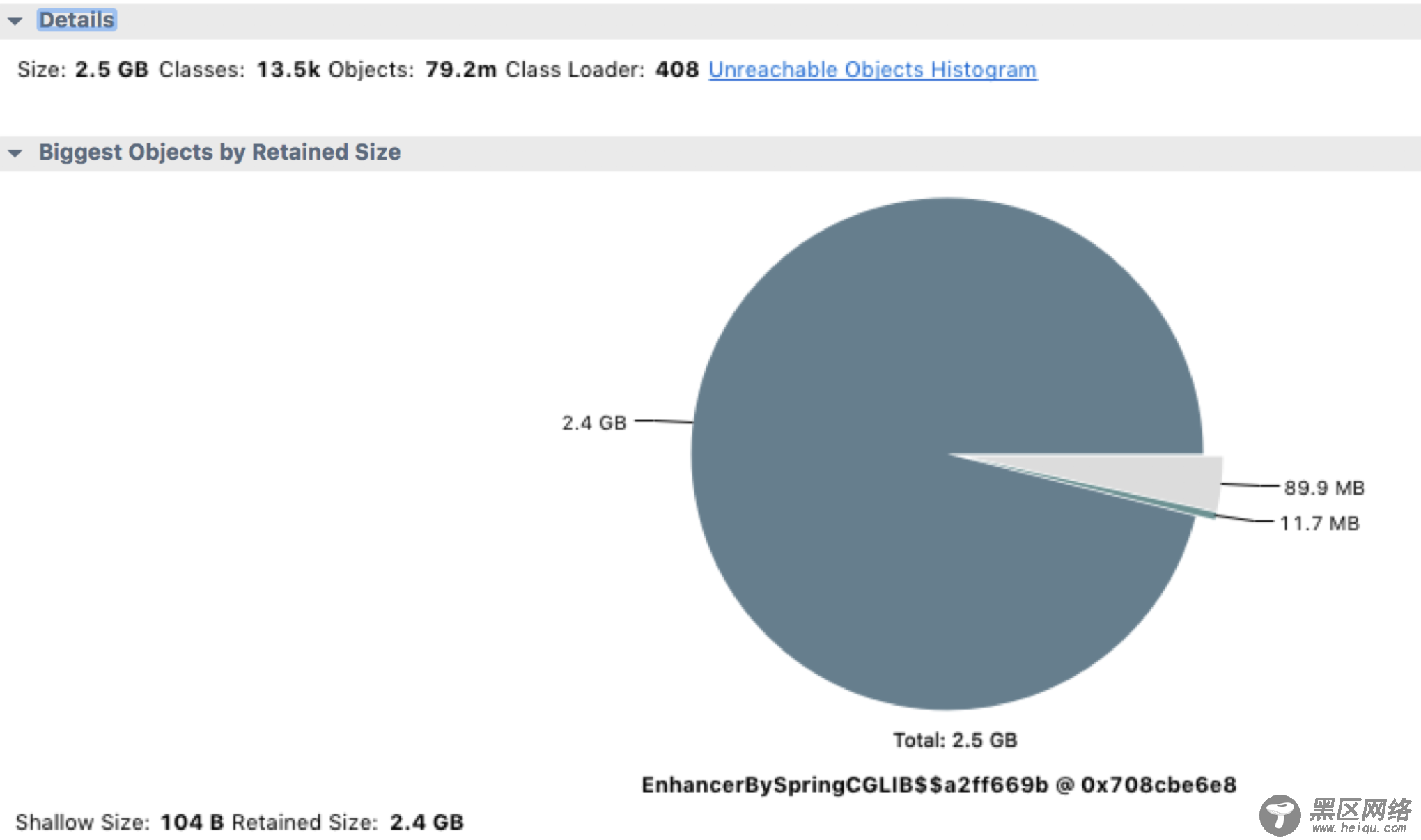
从上面的饼图中可以看出,绝大多数堆内存都被同一个内存占用了,再查看堆内存详情,向上层追溯,很快就发现了罪魁祸首。
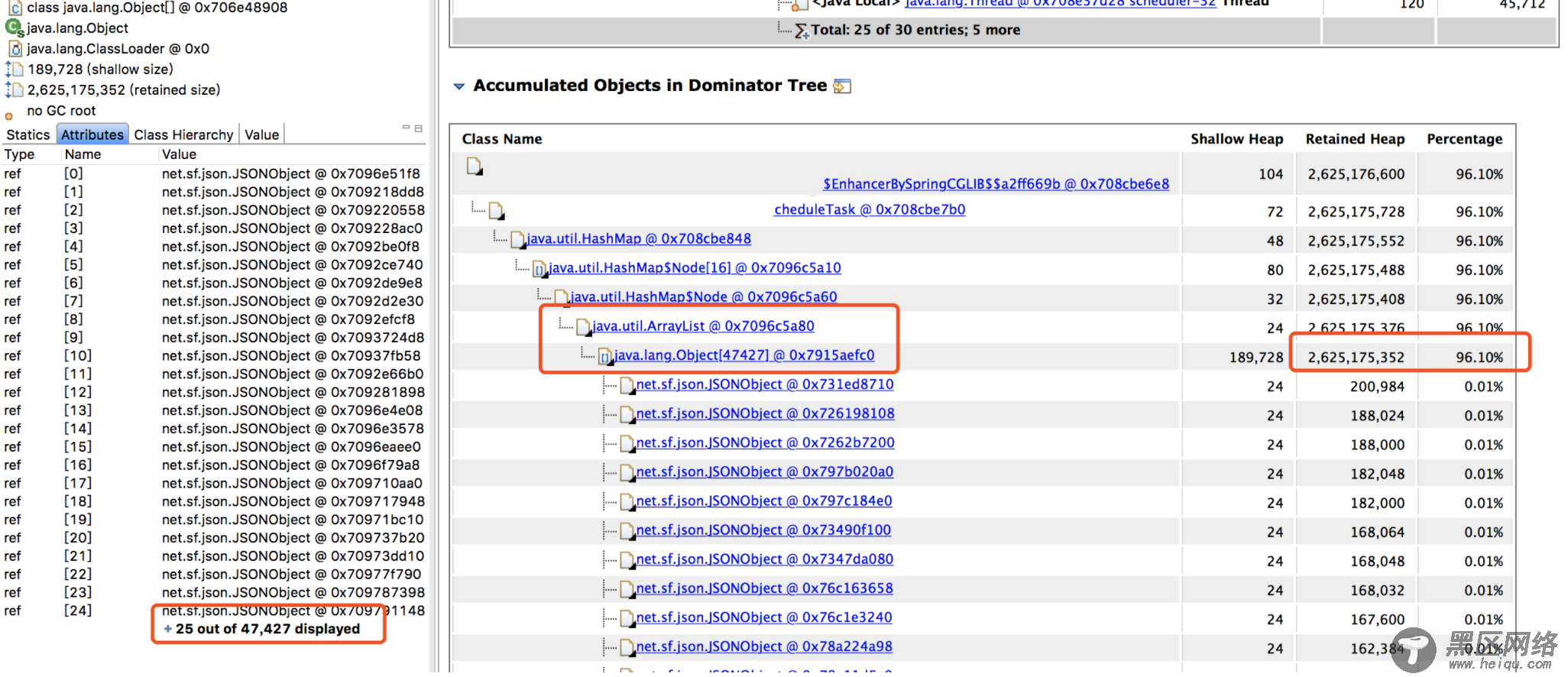
找到内存泄漏的对象了,在项目里全局搜索对象名,它是一��� Bean 对象,然后定位到它的一个类型为 Map 的属性。
这个 Map 根据类型用 ArrayList 存储了每次探测接口响应的结果,每次探测完都塞到 ArrayList 里去分析,由于 Bean 对象不会被回收,这个属性又没有清除逻辑,所以在服务十来天没有上线重启的情况下,这个 Map 越来越大,直至将内存占满。
内存满了之后,无法再给 HTTP 响应结果分配内存了,所以一直卡在 readLine 那。而我们那个大量 I/O 的接口报警次数特别多,估计跟响应太大需要更多内存有关。
给代码 owner 提了 PR,问题圆满解决。
小结其实还是要反省一下自己的,一开始报警邮件里还有这样的线程栈:
groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:166) groovy.json.internal.JsonParserCharArray.decodeJsonObject(JsonParserCharArray.java:132) groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:186) groovy.json.internal.JsonParserCharArray.decodeJsonObject(JsonParserCharArray.java:132) groovy.json.internal.JsonParserCharArray.decodeValueInternal(JsonParserCharArray.java:186)