本文实例讲述了PHP使用DOM对XML解析处理操作。分享给大家供大家参考,具体如下:
DOM(Document Object Model):文档对象模型。核心思想是:把 xml文件看作是一个对象模型,然后通过对象的方式来操作 xml 文件。
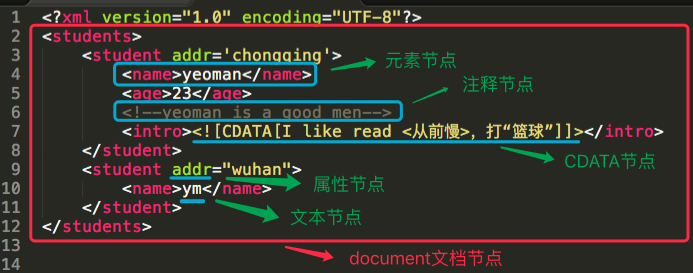
xml本身有许多节点:
元素节点
文本节点
属性节点
注释节点
CDATA节点
文档节点
php对xml文档进行增删改查(CURD)操作,具体分析如下:
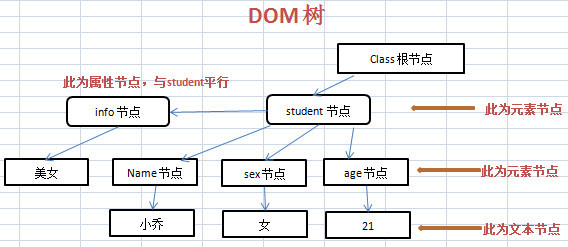
xml文档:class.xml
<?xml version="1.0" encoding="utf-8"?>
<class>
<student info="美女">
<name>小乔</name>
<sex>女</sex>
<age>20</age>
</student>
<student>
<name>周瑜</name>
<sex>男</sex>
<age>25</age>
</student>
</class>
php文件(对xml文档操作)
查询操作案例:
<?php
//1、创建一个DOMDocument对象。该对象就表示 xml文件
$xmldoc = new DOMDocument();
//2、加载xml文件(指定要解析哪个xml文件,此时dom树节点就会加载到内存中)
$xmldoc->load("class.xml");
//3、目标:获取第一个学生的名字
//3.1 第一步,读取所有的学生
/*方法getElementsByTagName:根据所给的节点名字(这里是student)查找 相应的节点,
返回 DOMNodeList类型的对象,相当于取出了所有的学生。
可以用var_dump($students)查看,并根据返回值查找手册,看其下面的属性与方法。*/
$students = $xmldoc->getElementsByTagName("student");
echo "共有 ".$students->length."个学生<br />";
//3.2 读取第一个学生
/*读取到第一个学生。返回值为DOMElement对象。
直接 echo $stu1->nodeValue;则把name,sex,age都输出。*/
$stu1 = $students->item(0);
//3.3 取出第一个学生的名字
$stu1_name = $stu1->getElementsByTagName("name");
//3.4 读取到名字
echo $stu1_name->item(0)->nodeValue;
?>
注意点:
(1)编码问题;
(2)这里只是基础演示,比较麻烦,后面用到循环和函数来操作;
(3)用var_dump(),查看变量的返回值是什么,再根据返回值到手册中查找该返回值下的属性与方法。
(4)整个顺序下来,getElementByTagName()并不需要一层一层的读,事实上可以直接读取到节点name的,而不需要先读取student(当然,如果同一个student下,有多个name,就会出问题了,这里就需要学习新的知识点xpath)。