7.编写Test文件用来在HDFS上存储文件并检查是否成功
import Java.io.IOException;
import org.apache.Hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Test {
public static void main(String[] args) {
Configuration conf = new Configuration();
try {
FileSystem fs = FileSystem.get(conf);
Path f = new Path("hdfs://localhost:9999/test.txt");
FSDataOutputStream out = fs.create(f);
for(int i=0;i<100;i++){
out.writeChars("test" + i + "\n");
}
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打包成test.jar并拷贝到hadoop/bin目录下,终端进入~/eric/hadoop/bin目录。
hadoop namenode -format (#格式化) start-all.sh (#启动) ./hadoop fs -ls / .hadoop jar ./test.jar Test ./hadoop fs -ls / ./hadoop fs -cat /test.txt stop-all.sh (#结束)下面的截图可以供参考:
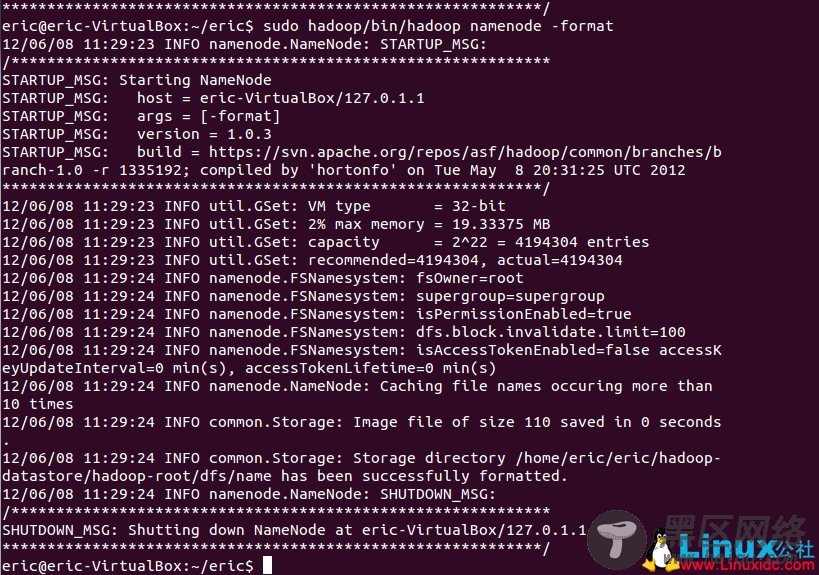


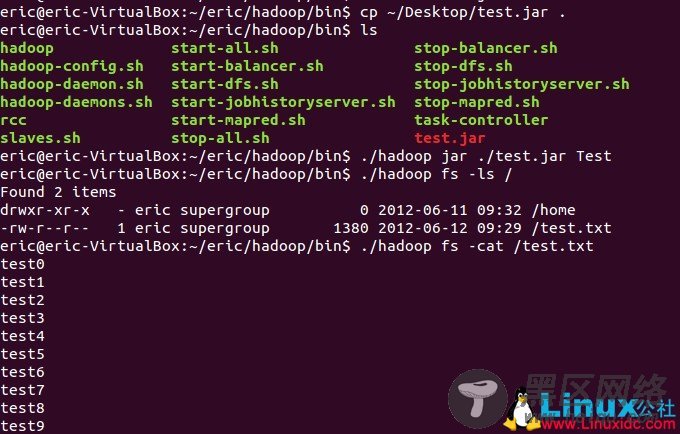

对于学习hadoop希望有帮助~ ^_^
补充:
1. 启动脚本
在Hadoop Wiki中看到如下对启动脚本的介绍,不清楚具体针对的版本是怎样,个人觉得可能是0.2.X之后的,这样也好,把HDFS和MapRed分开了。
start-dfs.sh - Starts the Hadoop DFS daemons, the namenode and datanodes. Use this before start-mapred.sh
stop-dfs.sh - Stops the Hadoop DFS daemons.
start-mapred.sh - Starts the Hadoop Map/Reduce daemons, the jobtracker and tasktrackers.
stop-mapred.sh - Stops the Hadoop Map/Reduce daemons.
start-all.sh - Starts all Hadoop daemons, the namenode, datanodes, the jobtracker and tasktrackers. Deprecated; use start-dfs.sh then start-mapred.sh
stop-all.sh - Stops all Hadoop daemons. Deprecated; use stop-mapred.sh then stop-dfs.sh