
[linuxidc@linuxidc119 hadoop-2.6.0]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /home/linuxidc/hadoop-2.6.0/logs/hadoop-linuxidc-namenode-linuxidc119.out
[linuxidc@linuxidc119 hadoop-2.6.0]$ jps
14401 JournalNode
15407 NameNode
15455 Jps
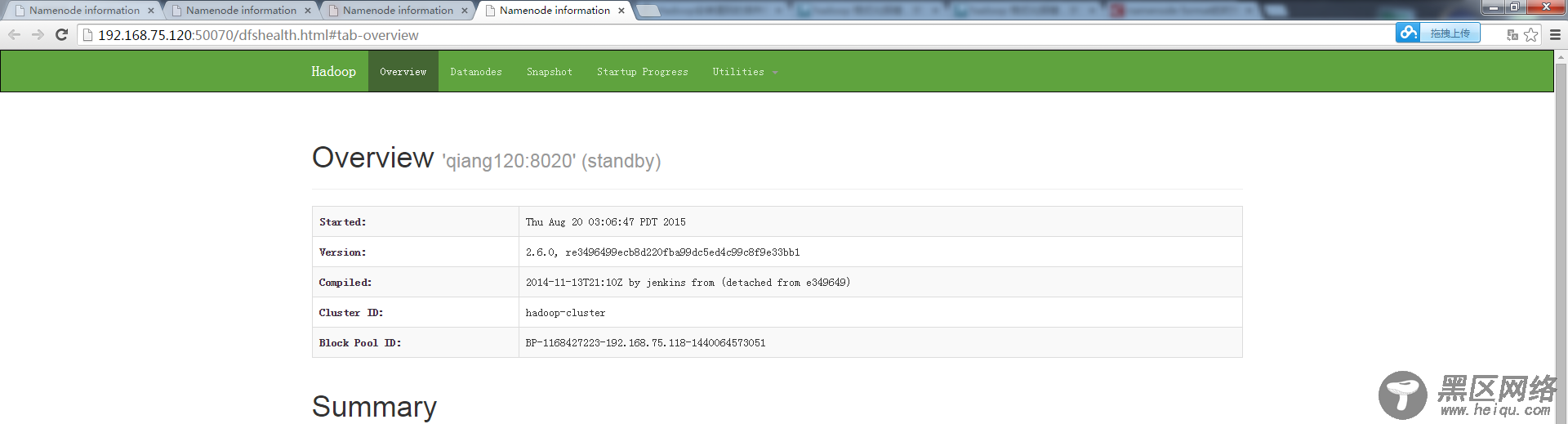
在web上 打开以后二个显示都是standy状态:
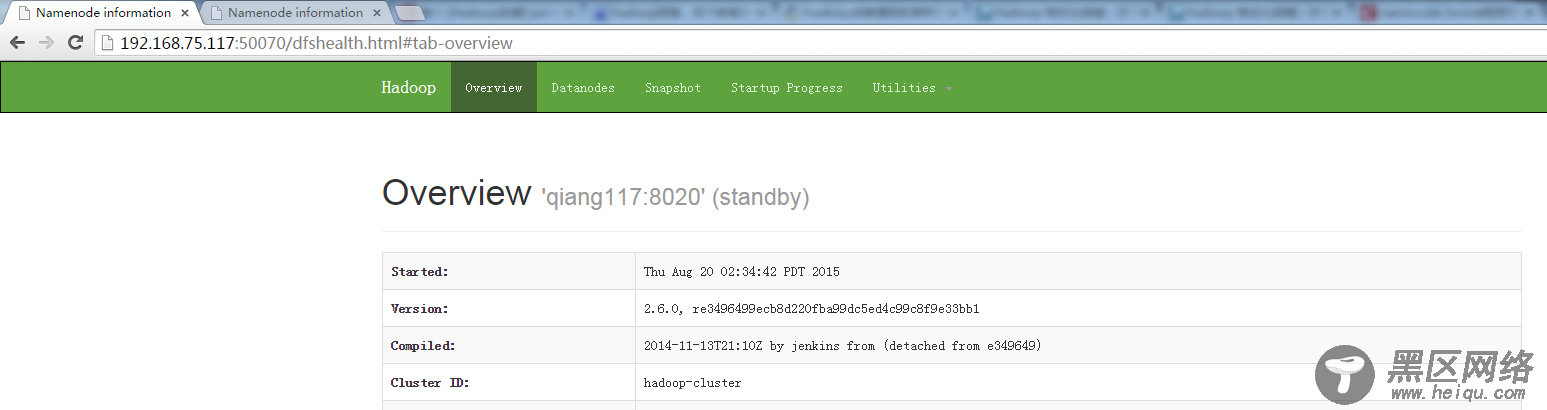
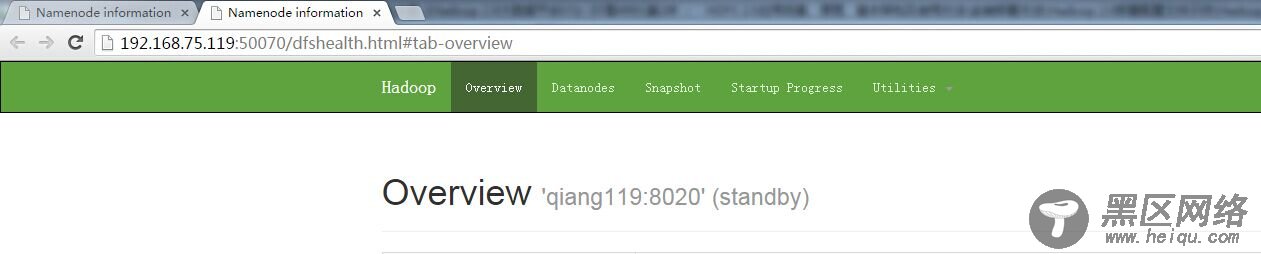
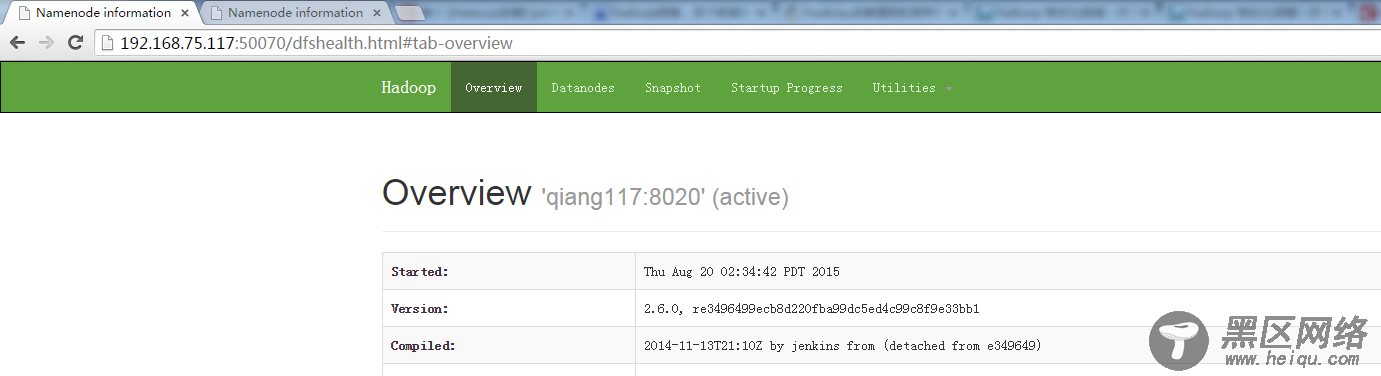
使用这个命令将nn1切换为active状态:
bin/hdfs haadmin -ns hadoop-cluster1 -transitionToActive nn1
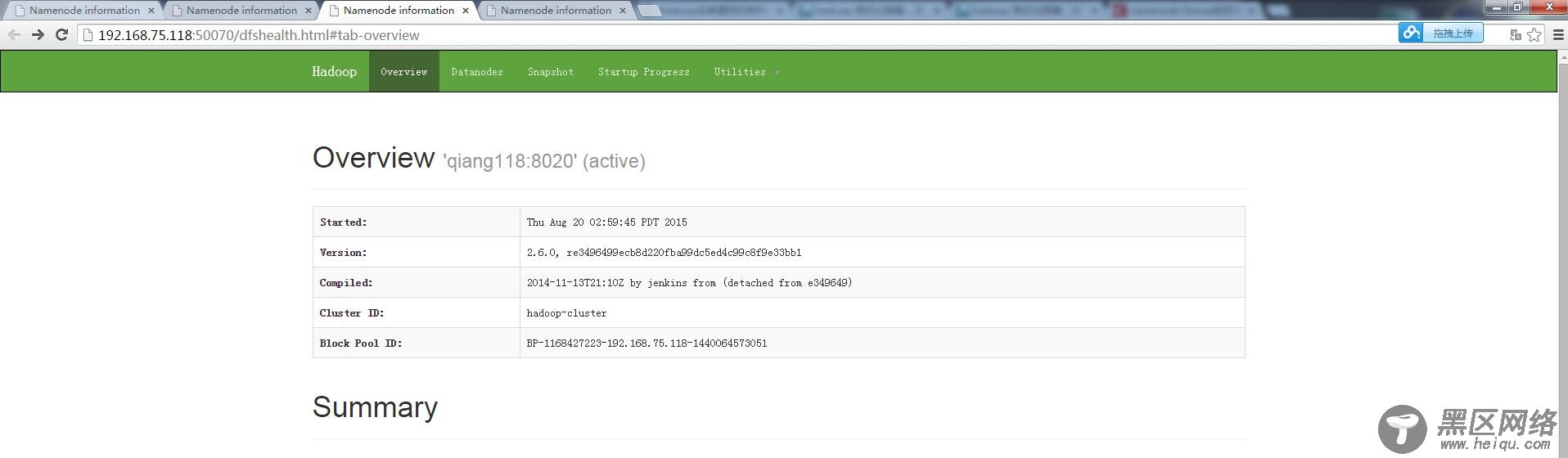
另外两个一样的道理:
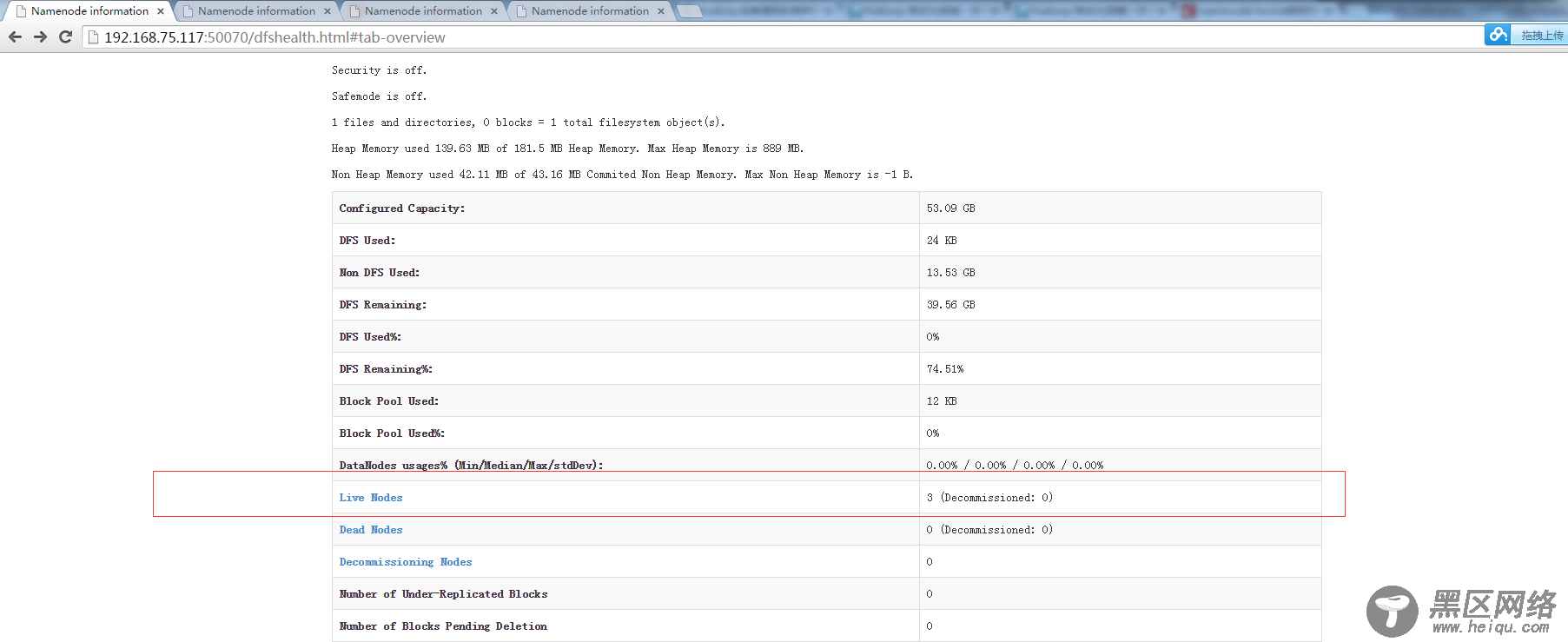
开启所有的datanode,这里是在只有配置好ssh免密码登录的情况下才能使用。可以参考:
[linuxidc@linuxidc117 hadoop-2.6.0]$ sbin/hadoop-daemons.sh start datanode
开了仨,就是之前预设好的192.168.1.118,192.168.1.119和192.168.1.120
启动yarn
[linuxidc@linuxidc117 hadoop-2.6.0]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/linuxidc/hadoop-2.6.0/logs/yarn-linuxidc-resourcemanager-linuxidc117.out
linuxidc118: nodemanager running as process 14812. Stop it first.
linuxidc120: nodemanager running as process 14025. Stop it first.
linuxidc119: nodemanager running as process 17590. Stop it first.
[linuxidc@linuxidc117 hadoop-2.6.0]$ jps
NameNode
Jps
ResourceManager
也是可以看到有三个datanode

最后总结一下吧...... 自学大数据的话,有一个简单的部署就足够了,能够让你写好的程序放入hdfs中跑就可以了,这样的集群应该是在最后,或者需要的时候再去详细的做研究,抓紧进入之后的阶段吧~~