
Redis在豌豆荚的使用历程——单实例==》多实例,业务代码中做sharding==》单个Twemproxy==》多个 Twemproxy==》Codis,豌豆荚自己开发的分布式Redis服务。在大规模的Redis使用过程中,他们发现Redis受限于多个方面:单机 内存有限、带宽压力、单点问题、不能动态扩容以及磁盘损坏时的数据抢救。

Redis通常有3个使用途径:客户端静态分片,一致性哈希;通过Proxy分片,即Twemproxy;还有就是官方的Redis Cluster,但至今无一个新版本。随后刘奇更详细的分析了为什么不使用Twemproxy和Redis Cluster:
Twemproxy:最大的痛点是无法平滑的扩容或者缩容,甚至修改配置都需要重启服务;其次,不可运维,甚至没有Dashboard。
Redis Cluster(官方):无中心化设计,程序难以编写;代码有点吓人,clusterProcessPacket函数有426行,人脑难以处理所有的状态 切换;迟迟没有正式版本,等了4年之久;目前还缺乏最佳实践,没有人编写Redis Cluster的若干条注意事项;整个系统高度耦合,升级困难。
虽然我们有众多的选择,比如 Tair 、 Couchbase 等,但是如果你需要更复杂和优秀的数据结构, Redis 可称为不二之选。基于这个原因,在 Redis 之上,豌豆荚设计了 Codis ,并将之开源。
Codis既然重新设计,那么 Codis 首先必须满足自动扩容和缩容的需求,其次则是必须避免单点故障和单点带宽不足,做一个高可用的系统。在这之后,基于原有的遗留系统,还必须可以轻松地将数据从 Twemproxy 迁移到 Codis ,并实现良好的运维和监控。基于这些, Codis 的设计跃然纸面:

然而,一个新系统的开发并不是件容易的事情,特别是一个复杂的分布式系统。刘奇表示,虽然当时团队只有 3 个人,但是他们几乎考量了可以考量的各种细节:
尽量拆分,简化每个模块,同时易于升级
每个组件只负责自己的事情
Redis 只作为存储引擎
Proxy 的状态
Redis 故障判定是否放到外部,因为分布式系统存活的判定异常复杂
提供 API 让外部调用,当 Redis Master 丢失时,提升 Slave 为 Master
图形化监控一切: slot 状态、 Proxy 状态、 group 状态、 lock 、 action 等等
而在考量了一切事情后,另一个争论摆在了眼前 ——Proxy 或者是 Smart Client : Proxy 拥有更好的监控和控制,同时其后端信息亦不易暴露,易于升级;而 Smart Client 拥有更好的性能,及更低的延时,但是升级起来却比较麻烦。对比种种优劣,他们最终选择了 Proxy ,无独有偶,在 codis 开源后, twitter 的一个分享提到他们也是基于 proxy 的设计。
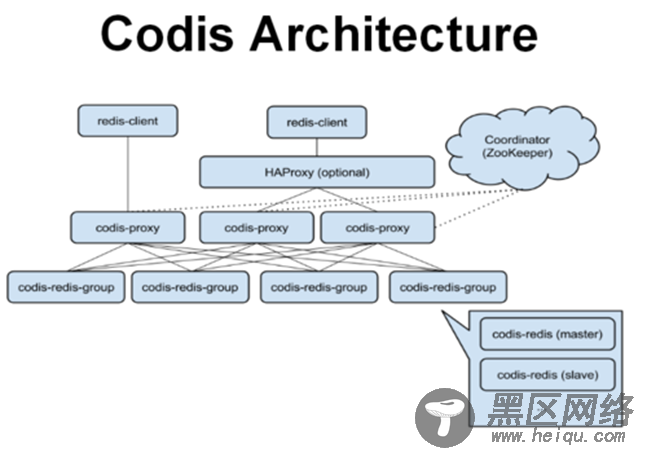
Codis 主要包含 Codis Proxy ( codis-proxy )、 Codis Manager ( codis-config )、 Codis Redis ( codis-server )和 ZooKeeper 四大组件,每个部分都可动态扩容。
codis-proxy 。 客户端连接的 Redis 代理服务,本身实现了 Redis 协议,表现很像原生的 Redis (就像 Twemproxy )。一个业务可以部署多个 codis-proxy ,其本身是无状态的。