
我们知道,在PG中,每个relation,也就是表,都有好几个fork对应。存放主表数据的为“MAIN” fork;管理空余空间的为“FSM” fork;存放可视化视图的为“visibility” fork。
那么PG又是如何将每个表的fork管理起来,并跟pg_class中的relfileno对应起来的呢?这可以分为两类:一类是常规表;一类是系统表。
1.常规表
假设我有一张表叫”tab_mvcc_test”,它在postgres数据库中。因此我们得先找到数据库目录。查pg_database,得到oid为“12896”。
接着去base目录下,找到相应的数据库目录。“12896”目录就是我们想要的。
然后从pg_class中,我们查到”tab_mvcc_test”的relfilenode为“16483”。

接着我们进入数据库目录“12896”,然后list一把,提到以下相关的三个文件。以“_fsm”后缀的就是Free Space Mapping文件。以”vm”后缀的就是visibility map。
而没有后缀的那个就是我们的主表数据文件,里面还存放了索引数据。

2.系统表
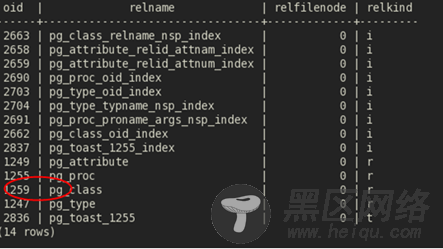
另外像系统的catalog表,如pg_class,它的refileno是”0“,又是什么原因呢?PG对于系统表处理,不能像常规表一样。这就有点类似于”鸡生蛋,还是蛋生鸡“。因为系统表是来管理常规表的。
PG对于这些catalog表,放到一个文件中去管理,将oid与relfileno做映射。这个文件就是著名的”pg_filenode.map“。这个文件的大小为512,刚好是一个OS disk sector的大小。
PG做了对齐处理,在源码上用RelMapFile结构体与之对应。结构体大小为:62*8+4*4=496+16=512。也就是说这个文件最多存放62条系统catalog表的记录。
由于这个文件的重要性,刚好与disk sector大小对齐,减少文件crash的机率。

我们接下来把pg_filenode.map DUMP出来看一下,里面是什么数据:
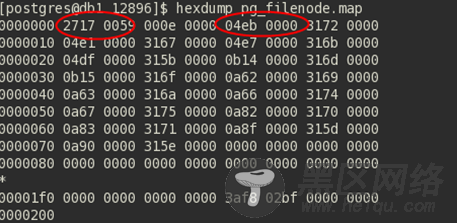
第一个圈中的数据为PG文件头的魔法数据字,那么第二个圈中的,到底对应的是哪个catalog表呢?我们可以计算下:“4eb”对应十进制数据就是”1259“,刚好是pg_class的oid。
而后面的”3172”对应的就是12658。刚好是relfilenode。完美的对应了起来。

再得到文件如下:

记录数刚好14,跟上面图中两个红色圈之间的数字”000e“对起来。这个文件还存放了这些系统表对应的索引文件filenode。
------------------------------------华丽丽的分割线------------------------------------
CentOS 6.3环境下yum安装PostgreSQL 9.3
PostgreSQL缓存详述
Ubuntu下LAPP(Linux+Apache+PostgreSQL+PHP)环境的配置与安装
PostgreSQL配置Streaming Replication集群
如何在CentOS 7/6.5/6.4 下安装PostgreSQL 9.3 与 phpPgAdmin
------------------------------------华丽丽的分割线------------------------------------