
supervisor、worker、executor等组件的心跳信息会同步至zookeeper,nimbus会周期性地获取这些信息,结合已分配的任务信息assignments、集群现有的topologies(已运行+未运行)等等信息,来进行任务分配,如下图所示:

1、通过rebalance和do-reblalance(比如来自web调用)触发负载均衡,会触发mk-assignments即任务分配。
2、同时,nimbus进程启动后,会周期性地进行任务分配。
3、客户端通过storm jar ... topology 方式提交topology,会通过thrift调用nimbus接口,提交topology,启动新storm实例,并触发任务分配。
负载均衡负载均衡和任务分配是连在一起的,或者说任务分配中所用到的关键信息是由负载均衡来主导计算的,上文已经分析了任务分配的主要角色和流程,那么负载均衡理解起来就很容易了,流程和框架如下图所示:
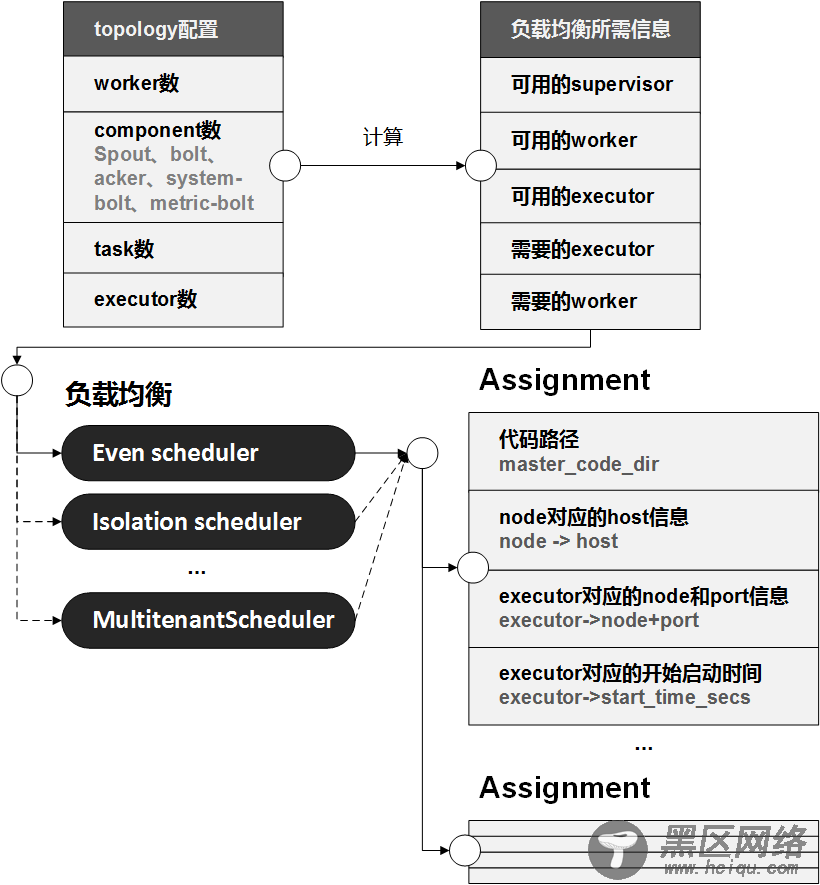
其中,负载均衡部分的策略可采用平均分配、机器隔离或topology隔离后再分配、Round-Robin等等,因为主要讨论storm的基础框架,而具体的负载均衡策略各家都不一样,而且这个策略是完全可以自定义的,比如可以将机器的实际能力如CPU、磁盘、内存、网络等等资源抽象为一个一个的资源slot,以此slot为单位进行分配,等等。
这里就不深入展开了。
通过负载均衡得出了新的任务分配信息assignments,nimbus再进行一些转换计算,就会将信息同步到zookeeper上,supervisor就可以根据这些信息来同步worker了。
结语本篇作为对上篇的补充和完善.
也完整地回答了这个问题:
在Topology中我们可以指定spout、bolt的并行度,在提交Topology时Storm如何将spout、bolt自动发布到每个服务器并且控制服务的CPU、磁盘等资源的?
终。