
为什么引入IF? 我们需要判断排序后自增的时候,案例来源是否和上次的一样,如果不一样 说明切换到了新来源,这时候将@ID设置为从1开始,就可以实现2个来源不同的自增ID。
要判断来源是否一样,我们还得加个临时变量 @CaseFrom
复制代码
SET @ID:=0,@CaseFrom='';
SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID,ResidentialAreaID,CaseFrom,Price,
@CaseFrom:=CaseFrom wy
FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY CaseFrom,Price;
这里的wy字段,就纯粹是为了赋值CaseFrom。对其他操作无用。
结果如下:
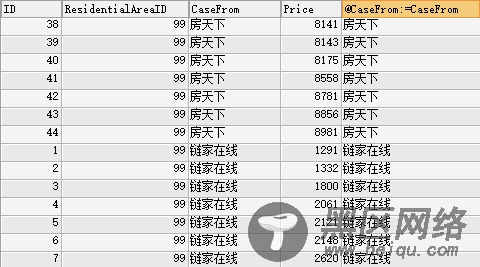
但是问题来了。 @ID已经不能直接用来 判断Count(*)/2了 。 因为@ID 已经是链家在线的ID,而不是房天下的。
通过创建临时表:临时完美通俗的解决该问题:
临时表Temporary只在当前会话使用,其余会话创建相同名称临时表,不互相冲突,不直接生成实体表。
但临时表不能自我关联。
复制代码
SET @ID:=0,@CaseFrom='';
DROP TABLE IF EXISTS CS_1;
CREATE TEMPORARY TABLE CS_1
SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID,ResidentialAreaID,CaseFrom,Price,@CaseFrom:=CaseFrom wy
FROM CaseRent WHERE ResidentialAreaID = 99 ORDER BY CaseFrom,Price;
DROP TABLE IF EXISTS CS_2;
CREATE TEMPORARY TABLE CS_2
SELECT CaseFrom,FLOOR(Max(ID)/2) CenterID FROM CS_1 GROUP BY CaseFrom;
SELECT * FROM CS_1 a INNER JOIN CS_2 b ON a.ID = b.CenterID AND a.CaseFrom=b.CaseFrom;
这就显的拖沓了,写了这么多代码,创建了2张临时表,关联后获取结果。 不过只是相对而言, 对于一些临时性的操作,计算、导出的时候,就算是python编写个脚本,其代码量也远远大于这些。
上述方式,通过临时表 + IF 的方式,实现了多层次的中位数获取。但是我们知道,通过IF判断,意味着我如果添加新的层次,例如:
1.获取每一个小区、每一个来源的中位数。
这样我们就得增加一个小区ID的临时变量,不仅案例来源改变,需要重置ID为1, 小区ID改变时,也要重置为1, 这样的代码如下:
复制代码
SET @ID:=0,@CaseFrom='',@ResidentialAreaID=0;
DROP TABLE IF EXISTS CS_1;
CREATE TEMPORARY TABLE CS_1
SELECT IF(@CaseFrom!=CaseFrom,@ID:=1,@ID:=@ID+1) AS ID,
IF(@ResidentialAreaID!=ResidentialAreaID,@ID:=1,1) AS ID2,
ResidentialAreaID,CaseFrom,Price,@CaseFrom:=CaseFrom wy,@ResidentialAreaID:=ResidentialAreaID wy2
FROM CaseRent ORDER BY ResidentialAreaID,CaseFrom,Price;
DROP TABLE IF EXISTS CS_2;
CREATE TEMPORARY TABLE CS_2
SELECT ResidentialAreaID,CaseFrom,FLOOR(Max(ID)/2) CenterID FROM CS_1 GROUP BY ResidentialAreaID,CaseFrom;
SELECT * FROM CS_1 a INNER JOIN CS_2 b ON a.ID = b.CenterID AND a.CaseFrom=b.CaseFrom
AND a.ResidentialAreaID=b.ResidentialAreaID;
多了一个IF判断,多了一个临时变量,多关联了一个字段。
这对熟悉并了解该逻辑的人来说并没有增加多少代码量,但其多了一层逻辑,需要了解,这就可能照成混淆。
看上去很多,其实相较于其他方式,已经很精简了,不过还没完,我们还有很多方法可以尝试!
例如编写Mysql 自定义函数、存储过程来实现,不过这就有点偏离了。
接下来换一种方式实现。
通过 GROUP_CONCAT 和 SUBSTRING_INDEX实现中位数算法
Group_concat 一般不会太陌生,一般伴随着Group By 使用,当然也可以不实用Group by
通过Group_concat 可以将结果字段 默认通过 逗号 分割,组成一个新的字符串。
例如:
SELECT GROUP_CONCAT(Price) FROM CaseRent WHERE ResidentialAreaID = 99;
其结果如下:
而GROUP_CONCAT中,还可以写一些SQL代码。例如
GROUP_CONCAT( Price ORDER BY Price )
或者:
GROUP_CONCAT( DISTINCT Price )
是不是很方便,可以自行排序、剔除重复等操作,组成一个新的字符串。
再介绍另一个函数:SUBSTRING_INDEX
先看一下结果:
SELECT SUBSTRING_INDEX('一批,数,据',',',1)
= 一批
SELECT SUBSTRING_INDEX('一批,数,据',',',2)
= 一批,数
SELECT SUBSTRING_INDEX('一批,数,据',',',3)
= 一批,数,据
很明确了, 第一个参数放字符串,第二个为分割字符,第三个为取到第几个字符。
那就再说一个 -1 , -1 很常见,Redis、python 中 分割、查找字符经常使用,意为反向取值, 例如:
SELECT SUBSTRING_INDEX('一批,数,据',',',-1)
= 据
结合这两种函数的特性,就能完成中位数获取了。
我们来看一下:
SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(GROUP_CONCAT(Price ORDER BY Price),',',Count(1)/2),',',-1) zws
FROM CaseRent WHERE ResidentialAreaID = 99;
以上涉及了2个函数, SUBSTRING_INDEX 以及 GROUP_CONCAT,