HDFS Append时packet的格式以及DataNode对block/checksum文件的处理
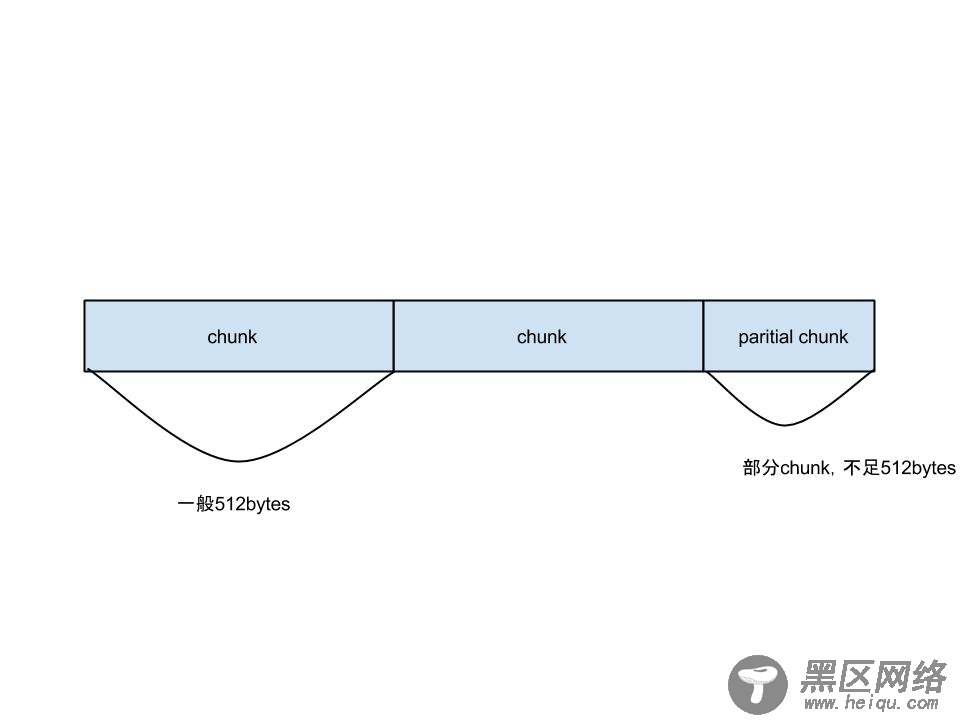
HDFS的Block一般比较大,默认64MB/128MB,客户端给DataNode发数据实际上是以Packet的形式发送的,Packet一般只有64KB左右。Packet内部由分为一个个chunk,每个chunk一般情况(后面会说非一般情况)下512Bytes,并且Packet内部对于每个chunk会带上这个chunk的checksum,对于CRC来说,checksum本身占用4Bytes。一个Packet的结构如下:

其中header中包含了一些元信息,比如这个packet是不是所属block的最后一个packet,数据长度多少,编码多少,packet的数据部分的第一个字节在block中的offset,DataNode接到这个Packet是否必须sync磁盘。
下面主要关注当客户端使用如下模式写数据时,数据是怎样被封装成一个个packet的:
FSDataOutputStream out = fs.append(new Path(file)); out.write(b, off, len); out.hflush()首先,假设需要进行append的file一开始不存在,没有任何数据。
实际上,out是HdfsDataOutputStream类型,out.write(b,off,len)最终调用了HdfsDataOutputStream包含的DFSOutputStream类型对象,转而调用的是DFSOutputStream的父类FSOutputSummer的write(b,off,len),FSOutputSummer从名字可以看出,对数据进行了checksum.
FSOutputSummer的write(b,off,len)实质上就一行:
for (int n=0;n<len;n+=write1(b, off+n, len-n)) {}实际上就是循环的调用write1方法将数据写入,write1方法会去检查是否写入的数据满了一个chunk(正常情况下512Bytes),如果满了,则为这个chunk计算一个checksum,4个字节,然后将这个chunk和对应的checksum写入当前Packet中(DFSOutputStream的writeChunk方法),格式就是上面那个图中的格式。当Packet满了,也就是说塞入的chunk的个数到达了预先计算的值,就将这个packet放入dataQueue,后台会有一个DataStreamer线程专门从这个dataQueue中取一个个的packet发送出去。
到这里,都比较清晰,需要注意的是,如果append的file中本身已经存在了一些数据,比如512+512+100Bytes,那么在调用out.write(b,off,len)向file中追加新的数据时,构造的第一个packet中只有一个chunk,并且这个chunk的大小是512-100=412Bytes,这个packet之后的packet的chunk是标准512Bytes。
if (appendChunk && bytesCurBlock%bytesPerChecksum == 0) { appendChunk = false; // 下次计算checksum时的chunk大小是512Bytes,不再是412Bytes resetChecksumChunk(bytesPerChecksum); }以上代码来自DFSOutputStream的writeChunk方法,其中appendChunk在fs.append时会被置为true,并且bytesCurBlock会初始化为append之前文件的大小,当构造完特殊包后,bytesCurBlock增加了412Bytes,将上次的paritial chunk补齐了。
DataStreamer从dataQueue中取packet发送出去的过程不关注,下面看DataNode针对append如何处理block文件和block的checksum文件。
DataNode上接受Block的逻辑封装在BlockReceiver中,其中,receiveBlock方法中有一段代码
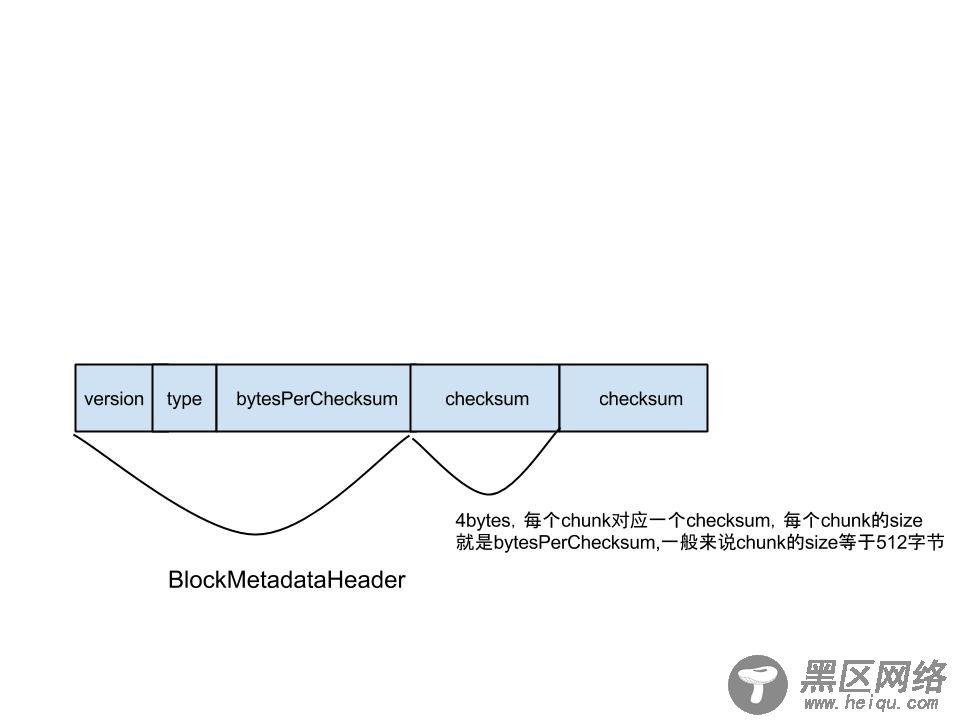
while (receivePacket() >= 0) { /* Receive until the last packet */ }每调一次receivePacket,DataNode就接收一个packet,将packet的data和checksum都拿出来,进行一次校验,看数据在发送过程中是否损坏,然后看block在当前DataNode上的副本在磁盘上的长度是否是chunk的整数倍,如果不是,则将block checksum文件(blk_1100893627_27540491.meta)的输出流seek到最后一个checksum,并且将最后一个checksum读出来,如下代码:
if (onDiskLen % bytesPerChecksum != 0) { // prepare to overwrite last checksum adjustCrcFilePosition(); } // If this is a partial chunk, then read in pre-existing checksum if (firstByteInBlock % bytesPerChecksum != 0) { LOG.info("Packet starts at " + firstByteInBlock + " for " + block + " which is not a multiple of bytesPerChecksum " + bytesPerChecksum); long offsetInChecksum = BlockMetadataHeader.getHeaderSize() + onDiskLen / bytesPerChecksum * checksumSize; computePartialChunkCrc(onDiskLen, offsetInChecksum, bytesPerChecksum); }然后将数据写入block文件(blk_1100893627),将checksum写入block checksum文件(blk_1100893627_27540491.meta)
block file和block checksum file格式如下: