
(二) 第2步:上传模拟数据文件夹。
为了运行程序,我们需要一个输入的文件夹,和输出的文件夹。
在本地新建word.txt
java c++ python c
java c++ javascript
helloworld Hadoop
mapreduce java hadoop hbase
通过hadoop的命令在HDFS上创建/tmp/workcount目录,命令如下:
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -mkdir /tmp/wordcount/
通过copyFromLocal命令把本地的word.txt复制到HDFS上,命令如下:
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -copyFromLocal /tmp/word.txt /tmp/wordcount/word.txt
/tmp/word.txt是本地创建txt文件的路径,/tmp/wordcount/word.txt是HDFS上的路径。
(三) 第3步:运行项目
在新建的项目WordCount,点击WordCount.java,右键-->Run As-->Run Configurations
在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
hdfs://localhost:9000/tmp/wordcount/word.txt hdfs:// localhost:9000/tmp/wordcount/out
如果运行时报java.lang.OutOfMemoryError: Java heap space 配置VM arguments(在Program arguments下)
-Xms512m -Xmx1024m -XX:MaxPermSize=256m
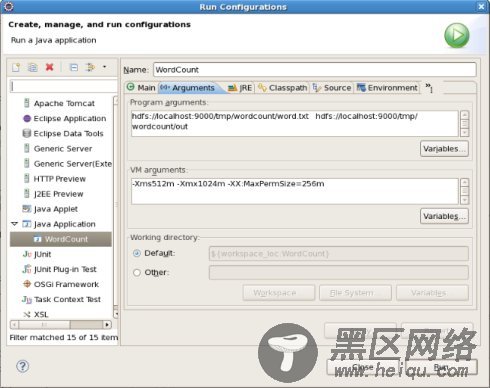
点击Run,运行程序。
点击Run,运行程序,过段时间将运行完成,等运行结束后,查看运行结果,使用命令:
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -ls /tmp/wordcount/out
Found 2 items
-rw-r--r-- 3 test supergroup 0 2012-11-01 11:32 /tmp/wordcount/out/_SUCCESS
-rw-r--r-- 3 test supergroup 81 2012-11-01 11:32 /tmp/wordcount/out/part-r-00000
查看例子的输出结果,发现有两个文件,使用命令查看part-r-00000文件,可以查看运行结果。
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000
c 1
c++ 2
hadoop 2
hbase 1
helloworld 1
java 3
javascript 1
mapreduce 1
python 1
删除到运行结果:
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -rmr /tmp/wordcount/out
Deleted hdfs://localhost:9000/tmp/wordcount/out
再次Run程序后查看结果:
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -ls /tmp/wordcount/out
Found 2 items
-rw-r--r-- 3 test supergroup 0 2012-11-01 11:37 /tmp/wordcount/out/_SUCCESS
-rw-r--r-- 3 test supergroup 81 2012-11-01 11:37 /tmp/wordcount/out/part-r-00000
[test@localhost hadoop-1.0.4]$ bin/hadoop fs -cat /tmp/wordcount/out/part-r-00000
c 1
c++ 2
hadoop 2
hbase 1
helloworld 1
java 3
javascript 1
mapreduce 1
python 1
5 Hadoop包介绍
Hadoop API被分成如下几种主要的包(package):
org.apache.hadoop.conf
定义了系统参数的配置文件处理API
org.apache.hadoop.fs
定义了抽象的文件系统API
org.apache.hadoop.dfs
Hadoop分布式文件系统(HDFS)模块的实现
org.apache.hadoop.io
定义了通用的I/O API,用于针对网络,数据库,文件等数据对象做读写操作
org.apache.hadoop.ipc
用于网络服务端和客户端的工具,封装了网络异步I/O的基础模块
org.apache.hadoop.mapred
Hadoop分布式计算系统(MapReduce)模块的实现,包括任务的分发调度等
org.apache.hadoop.metrics
定义了用于性能统计信息的API,主要用于mapred和dfs模块
org.apache.hadoop.record
定义了针对记录的I/O API类以及一个记录描述语言翻译器,用于简化将记录序列化成语言中性的格式(language-neutral manner)
org.apache.hadoop.tools
定义了一些通用的工具
org.apache.hadoop.util
定义了一些公用的API