5.1 配置群集的工作属性
corosync默认启用了stonith,而当前集群并没有相应的stonith设备,因此此默认配置目前尚不可用,这可以通过如下命令先禁用stonith:
[root@node1 corosync]# cd
[root@node1 ~]# crm configure property stonith-enabled=false
[root@node1 ~]#
[root@node2 corosync]# cd
[root@node2 ~]# crm configure property stonith-enabled=false
[root@node2 ~]#
对于双节点的集群来说,我们要配置此选项来忽略quorum,即这时候票数不起作用,一个节点也能正常运行:
[root@node1 ~]#
[root@node1 ~]# crm configure property no-quorum-policy=ignore
[root@node1 ~]#
[root@node2 ~]#
[root@node2 ~]# crm configure property no-quorum-policy=ignore
[root@node2 ~]#
定义资源的粘性值,使资源不能再节点之间随意的切换,因为这样是非常浪费系统的资源的。
资源黏性值范围及其作用:
0:这是默认选项。资源放置在系统中的最适合位置。这意味着当负载能力“较好”或较差的节点变得可用时才转移资源。此选项的作用基本等同于自动故障回复,只是资源可能会转移到非之前活动的节点上;
大于0:资源更愿意留在当前位置,但是如果有更合适的节点可用时会移动。值越高表示资源越愿意留在当前位置;
小于0:资源更愿意移离当前位置。绝对值越高表示资源越愿意离开当前位置;
INFINITY:如果不是因节点不适合运行资源(节点关机、节点待机、达到migration-threshold 或配置更改)而强制资源转移,资源总是留在当前位置。此选项的作用几乎等同于完全禁用自动故障回复;
-INFINITY:资源总是移离当前位置;
我们这里可以通过以下方式为资源指定默认黏性值:
[root@node1 ~]#
[root@node1 ~]# crm configure rsc_defaults resource-stickiness=100
[root@node1 ~]#
[root@node2 ~]#
[root@node2 ~]# crm configure rsc_defaults resource-stickiness=100
[root@node2 ~]#
5.2 定义群集服务及资源
5.2.1 改变drbd的状态
[root@node2 ~]# drbd-overview
0:MySQL Connected Primary/Secondary UpToDate/UpToDate C r----
[root@node2 ~]# drbdadm secondary mysql
[root@node2 ~]# drbd-overview
0:mysql Connected Secondary/Secondary UpToDate/UpToDate C r----
[root@node2 ~]#
[root@node1 ~]# drbd-overview
0:mysql Connected Secondary/Secondary UpToDate/UpToDate C r----
[root@node1 ~]# drbdadm primary mysql
[root@node1 ~]# drbd-overview
0:mysql Connected Primary/Secondary UpToDate/UpToDate C r----
[root@node1 ~]#
5.2.2 配置drbd为群集资源
1、查看当前集群的配置信息,确保已经配置全局属性参数为两节点集群所适用
[root@node1 ~]# crm configure show
node node1.linuxidc.com
node node2.linuxidc.com
property $id="cib-bootstrap-options" \
dc-version="1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
rsc_defaults $id="rsc-options" \
resource-stickiness="100"
[root@node1 ~]#
2、将已经配置好的DRBD设备/dev/drbd0定义为集群服务;
[root@node1 ~]# service drbd stop
Stopping all DRBD resources: .
[root@node1 ~]# chkconfig drbd off
[root@node1 ~]# ssh node2 'service drbd stop'
Stopping all DRBD resources: .
[root@node1 ~]# ssh node2 'chkconfig drbd off'
[root@node1 ~]# drbd-overview
drbd not loaded
[root@node1 ~]# ssh node2 'drbd-overview'
drbd not loaded
[root@node1 ~]#
3、配置drbd为集群资源:
提供drbd的RA目前由OCF归类为linbit,其路径为/usr/lib/ocf/resource.d/linbit/drbd。我们可以使用如下命令来查看此RA及RA的meta信息:
[root@node1 ~]# crm ra classes
heartbeat
lsb
ocf / heartbeat linbit pacemaker
stonith
[root@node1 ~]# crm ra list ocf linbit
drbd
[root@node1 ~]#
4、查看drbd的资源代理的相关信息:
[root@node1 ~]# crm ra info ocf:linbit:drbd
This resource agent manages a DRBD resource
as a master/slave resource. DRBD is a shared-nothing replicated storage
device. (ocf:linbit:drbd)
Master/Slave OCF Resource Agent for DRBD
Parameters (* denotes required, [] the default):
drbd_resource* (string): drbd resource name
The name of the drbd resource from the drbd.conf file.
drbdconf (string, [/etc/drbd.conf]): Path to drbd.conf
Full path to the drbd.conf file.
Operations' defaults (advisory minimum):
start timeout=240
promote timeout=90
demote timeout=90
notify timeout=90
stop timeout=100
monitor_Slave interval=20 timeout=20 start-delay=1m
monitor_Master interval=10 timeout=20 start-delay=1m
[root@node1 ~]#
5、drbd需要同时运行在两个节点上,但只能有一个节点(primary/secondary模型)是Master,而另一个节点为Slave;因此,它是一种比较特殊的集群资源,其资源类型为多状态(Multi-state)clone类型,即主机节点有Master和Slave之分,且要求服务刚启动时两个节点都处于slave状态。
[root@node1 ~]# crm
crm(live)# configure
crm(live)configure# primitive mysqldrbd ocf:heartbeat:drbd params drbd_resource="mysql" op monitor role="Master" interval="30s" op monitor role="Slave" interval="31s" op start timeout="240s" op stop timeout="100s"
crm(live)configure# ms MS_mysqldrbd mysqldrbd meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify="true"
crm(live)configure# show mysqldrbd
primitive mysqldrbd ocf:heartbeat:drbd \
params drbd_resource="mysql" \
op monitor interval="30s" role="Master" \
op monitor interval="31s" role="Slave" \
op start interval="0" timeout="240s" \
op stop interval="0" timeout="100s"
crm(live)configure# show MS_mysqldrbd
ms MS_mysqldrbd mysqldrbd \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
确定无误后,提交:
crm(live)configure# verify
crm(live)configure# commit
crm(live)configure# exit
bye
[root@node1 ~]#
6、查看当前集群运行状态:
[root@node1 ~]# crm status
============
Last updated: Tue Feb 7 23:51:09 2012
Stack: openais
Current DC: node1.linuxidc.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ node2.linuxidc.com node1.linuxidc.com ]
Master/Slave Set: MS_mysqldrbd [mysqldrbd]
Masters: [ node1.linuxidc.com ]
Slaves: [ node2.linuxidc.com ]
[root@node1 ~]#
由上面的信息可以看出此时的drbd服务的Primary节点为node1.linuxidc.com,Secondary节点为node2.linuxidc.com。当然,也可以在node1上使用如下命令验正当前主机是否已经成为mysql资源的Primary节点:
[root@node1 ~]# drbdadm role mysql
Primary/Secondary
[root@node1 ~]# drbd-overview
0:mysql Connected Primary/Secondary UpToDate/UpToDate C r----
[root@node1 ~]#
我们实现将drbd设置自动挂载至/mysqldata目录。此外,此自动挂载的集群资源需要运行于drbd服务的Master节点上,并且只能在drbd服务将某节点设置为Primary以后方可启动。
确保两个节点上的设备已经卸载:
[root@node1 ~]# umount /dev/drbd0
[root@node2 ~]# umount /dev/drbd0
以下还在node1上操作:
[root@node1 ~]# crm
crm(live)# configure
crm(live)configure# primitive MysqlFS ocf:heartbeat:Filesystem params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" op start timeout=60s op stop timeout=60s
crm(live)configure#
crm(live)configure# show changed
primitive MysqlFS ocf:heartbeat:Filesystem \
params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" \
op start interval="0" timeout="60s" \
op stop interval="0" timeout="60s"
crm(live)configure#
crm(live)configure# commit
crm(live)configure# exit
bye
[root@node1 ~]#
7、mysql资源的定义(node1上操作)
先为mysql集群创建一个IP地址资源,通过集群提供服务时使用,这个地址就是客户端访问mysql服务器使用的ip地址;
[root@node1 ~]# crm configure primitive myip ocf:heartbeat:IPaddr params ip=192.168.101.88
[root@node1 ~]# crm configure primitive mysqlserver lsb:mysqld
[root@node1 ~]# crm status
============
Last updated: Wed Feb 8 00:01:23 2012
Stack: openais
Current DC: node1.linuxidc.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
4 Resources configured.
============
Online: [ node2.linuxidc.com node1.linuxidc.com ]
Master/Slave Set: MS_mysqldrbd [mysqldrbd]
Masters: [ node1.linuxidc.com ]
Slaves: [ node2.linuxidc.com ]
MysqlFS (ocf::heartbeat:Filesystem): Started node1.linuxidc.com
myip (ocf::heartbeat:IPaddr): Started node2.linuxidc.com
mysqlserver (lsb:mysqld): Started node1.linuxidc.com
[root@node1 ~]#
8、配置资源的各种约束:
集群拥有所有必需资源,但它可能还无法进行正确处理。资源约束则用以指定在哪些群集节点上运行资源,以何种顺序装载资源,以及特定资源依赖于哪些其它资源。pacemaker共给我们提供了三种资源约束方法:
1)Resource Location(资源位置):定义资源可以、不可以或尽可能在哪些节点上运行
2)Resource Collocation(资源排列):排列约束用以定义集群资源可以或不可以在某个节点上同时运行
3)Resource Order(资源顺序):顺序约束定义集群资源在节点上启动的顺序。
定义约束时,还需要指定分数。各种分数是集群工作方式的重要组成部分。其实,从迁移资源到决定在已降级集群中停止哪些资源的整个过程是通过以某种方式修改分数来实现的。分数按每个资源来计算,资源分数为负的任何节点都无法运行该资源。在计算出资源分数后,集群选择分数最高的节点。INFINITY(无穷大)目前定义为 1,000,000。加减无穷大遵循以下3个基本规则:
1)任何值 + 无穷大 = 无穷大
2)任何值 - 无穷大 = -无穷大
3)无穷大 - 无穷大 = -无穷大
定义资源约束时,也可以指定每个约束的分数。分数表示指派给此资源约束的值。分数较高的约束先应用,分数较低的约束后应用。通过使用不同的分数为既定资源创建更多位置约束,可以指定资源要故障转移至的目标节点的顺序。
我们要定义如下的约束:
[root@node1 ~]# crm
crm(live)# configure
crm(live)configure# colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
crm(live)configure# order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
crm(live)configure# order myip_after_MysqlFS mandatory: MysqlFS myip
crm(live)configure# order mysqlserver_after_myip mandatory: myip mysqlserver
crm(live)configure# show changed
colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
order myip_after_MysqlFS inf: MysqlFS myip
order mysqlserver_after_myip inf: myip mysqlserver
crm(live)configure# verify
crm(live)configure# commit
crm(live)configure# exit
bye
[root@node1 ~]#
9.查看配置信息和状态,并测试:
[root@node1 ~]# crm configure show
node node1.linuxidc.com
node node2.linuxidc.com
primitive MysqlFS ocf:heartbeat:Filesystem \
params device="/dev/drbd0" directory="/mnt/mysqldata" fstype="ext3" \
op start interval="0" timeout="60s" \
op stop interval="0" timeout="60s"
primitive myip ocf:heartbeat:IPaddr \
params ip="192.168.101.88"
primitive mysqldrbd ocf:heartbeat:drbd \
params drbd_resource="mysql" \
op monitor interval="30s" role="Master" \
op monitor interval="31s" role="Slave" \
op start interval="0" timeout="240s" \
op stop interval="0" timeout="100s"
primitive mysqlserver lsb:mysqld
ms MS_mysqldrbd mysqldrbd \
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true"
colocation MysqlFS_with_mysqldrbd inf: MysqlFS MS_mysqldrbd:Master myip mysqlserver
order MysqlFS_after_mysqldrbd inf: MS_mysqldrbd:promote MysqlFS:start
order myip_after_MysqlFS inf: MysqlFS myip
order mysqlserver_after_myip inf: myip mysqlserver
property $id="cib-bootstrap-options" \
dc-version="1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f" \
cluster-infrastructure="openais" \
expected-quorum-votes="2" \
stonith-enabled="false" \
no-quorum-policy="ignore"
rsc_defaults $id="rsc-options" \
resource-stickiness="100"
[root@node1 ~]#
[root@node1 ~]# crm status
============
Last updated: Wed Feb 8 00:08:06 2012
Stack: openais
Current DC: node1.linuxidc.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
4 Resources configured.
============
Online: [ node2.linuxidc.com node1.linuxidc.com ]
Master/Slave Set: MS_mysqldrbd [mysqldrbd]
Masters: [ node1.linuxidc.com ]
Slaves: [ node2.linuxidc.com ]
MysqlFS (ocf::heartbeat:Filesystem): Started node1.linuxidc.com
myip (ocf::heartbeat:IPaddr): Started node1.linuxidc.com
mysqlserver (lsb:mysqld): Started node1.linuxidc.com
[root@node1 ~]#
可见,服务现在在node1上正常运行:
在node1上的操作,查看群集的运行状态:
[root@node1 ~]# service mysqld status
MySQL running (8720) [ OK ]
[root@node1 ~]# mount |grep drbd
/dev/drbd0 on /mnt/mysqldata type ext3 (rw)
[root@node1 ~]#
[root@node1 ~]# ll /mnt/mysqldata/
total 24
drwxr-xr-x 5 mysql mysql 4096 Feb 8 00:05 data
-rw-r--r-- 1 root root 4 Feb 7 21:28 f1
-rw-r--r-- 1 root root 0 Feb 7 21:28 f2
drwx------ 2 root root 16384 Feb 7 21:26 lost+found
[root@node1 ~]# ifconfig eth0:0
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:AE:83:D1
inet addr:192.168.101.88 Bcast:192.168.101.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
[root@node1 ~]#
在node2上的操作,查看群集的运行状态:
[root@node2 ~]# service mysqld status
MySQL is not running [FAILED]
[root@node2 ~]# mount |grep drbd
[root@node2 ~]# ll /mnt/mysqldata/
total 0
[root@node2 ~]# ifconfig eth0:0
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:D1:D4:32
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
[root@node2 ~]#
10.继续测试群集:
继续测试:
在node1上操作,让node1下线:
[root@node1 ~]# crm status
============
Last updated: Wed Feb 8 00:16:25 2012
Stack: openais
Current DC: node1.linuxidc.com - partition with quorum
Version: 1.1.5-1.1.el5-01e86afaaa6d4a8c4836f68df80ababd6ca3902f
2 Nodes configured, 2 expected votes
4 Resources configured.
============
Node node1.linuxidc.com: standby
Online: [ node2.linuxidc.com ]
Master/Slave Set: MS_mysqldrbd [mysqldrbd]
Masters: [ node2.linuxidc.com ]
Stopped: [ mysqldrbd:0 ]
MysqlFS (ocf::heartbeat:Filesystem): Started node2.linuxidc.com
myip (ocf::heartbeat:IPaddr): Started node2.linuxidc.com
mysqlserver (lsb:mysqld): Started node2.linuxidc.com
[root@node1 ~]#
在node2上的操作,查看群集的运行状态:
可见我们的资源已经都切换到了node2上:
[root@node2 ~]# service mysqld status
MySQL running (9093) [ OK ]
[root@node2 ~]# mount |grep drbd
/dev/drbd0 on /mnt/mysqldata type ext3 (rw)
[root@node2 ~]# ll /mnt/mysqldata/
total 24
drwxr-xr-x 5 mysql mysql 4096 Feb 8 00:16 data
-rw-r--r-- 1 root root 4 Feb 7 21:28 f1
-rw-r--r-- 1 root root 0 Feb 7 21:28 f2
drwx------ 2 root root 16384 Feb 7 21:26 lost+found
[root@node2 ~]# ifconfig eth0:0
eth0:0 Link encap:Ethernet HWaddr 00:0C:29:D1:D4:32
inet addr:192.168.101.88 Bcast:192.168.101.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
Interrupt:67 Base address:0x2000
[root@node2 ~]#
现在一切正常,我们可以验证mysql服务是否能被正常访问:
首先,在node2上面建立一个用户user1,密码:123456.
我们定义的是通过VIP:192.168.101.88来访问mysql服务,现在node2上建立一个可以让某个网段主机能访问的账户(这个内容会同步drbd设备同步到node1上):
[root@node2 ~]# mysql
...
mysql> grant all on *.* to user1@'192.168.%.%' identified by '123456';
Query OK, 0 rows affected (0.01 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
[root@node2 ~]#
客户端访问测试
192.168.101.100客户Ping测试192.168.101.88
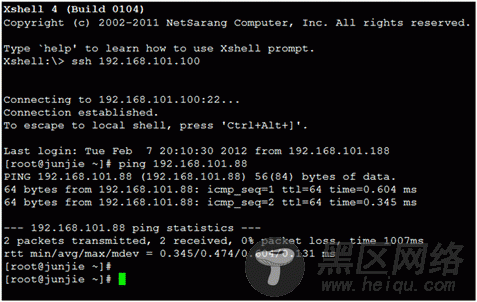
192.168.101.100客户访问mysql数据库192.168.101.88(成功访问)
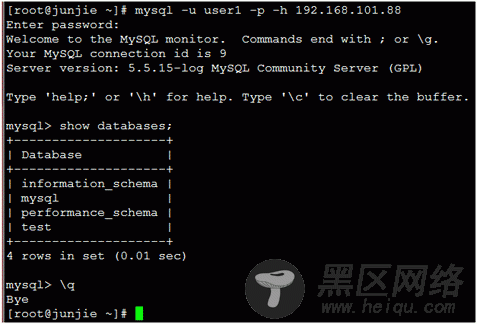
至此:使用corosync+drbd+pacemaker实现mysql服务器的高可用集群成功完成!.