
五、RCU 典型应用
在 linux 2.6 内核中,RCU 被内核使用的越来越广泛。下面是在最新的 2.6.12内核中搜索得到的RCU使用情况统计表。
表 1 rcu_read_lock 的使用情况统计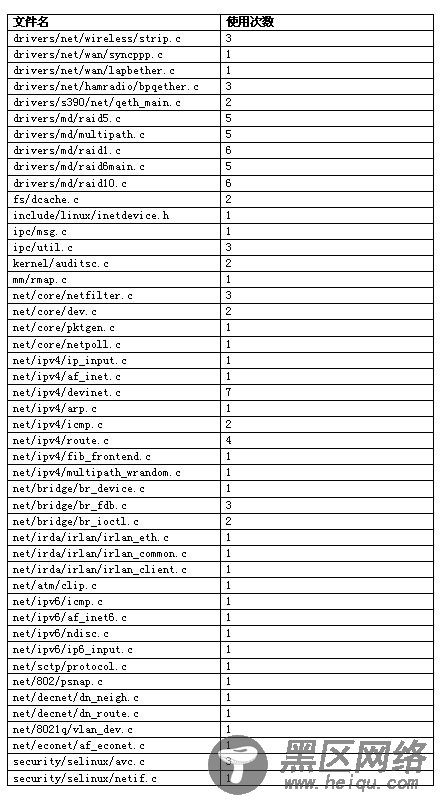





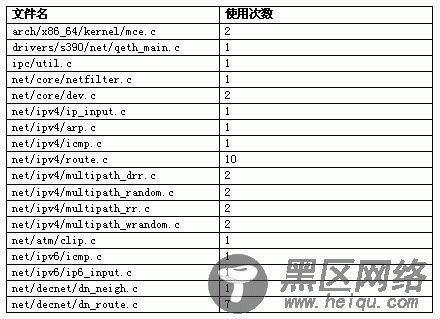
从以上统计结果可以看出,RCU已经在网络驱动层、网络核心层、IPC、dcache、内存设备层、软RAID层、系统调用审计和SELinux中使用。从所有RCU API的使用统计汇总(表 10),不难看出,RCU已经是一个非常重要的内核锁机制。
表 10 所有RCU API使用情况总汇
因此,如何正确使用 RCU 对于内核开发者而言非常重要。
下面部分将就 RCU 的几种典型应用情况详细讲解。
1.只有增加和删除的链表操作
在这种应用情况下,绝大部分是对链表的遍历,即读操作,而很少出现的写操作只有增加或删除链表项,并没有对链表项的修改操作,这种情况使用RCU非常容易,从rwlock转换成RCU非常自然。路由表的维护就是这种情况的典型应用,对路由表的操作,绝大部分是路由表查询,而对路由表的写操作也仅仅是增加或删除,因此使用RCU替换原来的rwlock顺理成章。系统调用审计也是这样的情况。
这是一段使用rwlock的系统调用审计部分的读端代码:
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; read_lock(&auditsc_lock); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { read_unlock(&auditsc_lock); return state; } } read_unlock(&auditsc_lock); return AUDIT_BUILD_CONTEXT; }
使用RCU后将变成:
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; rcu_read_lock(); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry_rcu(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { rcu_read_unlock(); return state; } } rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; }
这种转换非常直接,使用rcu_read_lock和rcu_read_unlock分别替换read_lock和read_unlock,链表遍历函数使用_rcu版本替换就可以了。
使用rwlock的写端代码:
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; write_lock(&auditsc_lock); list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { list_del(&e->list); write_unlock(&auditsc_lock); return 0; } } write_unlock(&auditsc_lock); return -EFAULT; /* No matching rule */ } static inline int audit_add_rule(struct audit_entry *entry, struct list_head *list) { write_lock(&auditsc_lock); if (entry->rule.flags & AUDIT_PREPEND) { entry->rule.flags &= ~AUDIT_PREPEND; list_add(&entry->list, list); } else { list_add_tail(&entry->list, list); } write_unlock(&auditsc_lock); return 0; }
使用RCU后写端代码变成为:
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; /* Do not use the _rcu iterator here, since this is the only * deletion routine. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { list_del_rcu(&e->list); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ } static inline int audit_add_rule(struct audit_entry *entry, struct list_head *list) { if (entry->rule.flags & AUDIT_PREPEND) { entry->rule.flags &= ~AUDIT_PREPEND; list_add_rcu(&entry->list, list); } else { list_add_tail_rcu(&entry->list, list); } return 0; }
对于链表删除操作,list_del替换为list_del_rcu和call_rcu,这是因为被删除的链表项可能还在被别的读者引用,所以不能立即删除,必须等到所有读者经历一个quiescent state才可以删除。另外,list_for_each_entry并没有被替换为list_for_each_entry_rcu,这是因为,只有一个写者在做链表删除操作,因此没有必要使用_rcu版本。
通常情况下,write_lock和write_unlock应当分别替换成spin_lock和spin_unlock,但是对于只是对链表进行增加和删除操作而且只有一个写者的写端,在使用了_rcu版本的链表操作API后,rwlock可以完全消除,不需要spinlock来同步读者的访问。对于上面的例子,由于已经有audit_netlink_sem被调用者保持,所以spinlock就没有必要了。
这种情况允许修改结果延后一定时间才可见,而且写者对链表仅仅做增加和删除操作,所以转换成使用RCU非常容易。
2.写端需要对链表条目进行修改操作
如果写者需要对链表条目进行修改,那么就需要首先拷贝要修改的条目,然后修改条目的拷贝,等修改完毕后,再使用条目拷贝取代要修改的条目,要修改条目将被在经历一个grace period后安全删除。
对于系统调用审计代码,并没有这种情况。这里假设有修改的情况,那么使用rwlock的修改代码应当如下:
static inline int audit_upd_rule(struct audit_rule *rule, struct list_head *list, __u32 newaction, __u32 newfield_count) { struct audit_entry *e; struct audit_newentry *ne; write_lock(&auditsc_lock); /* Note: audit_netlink_sem held by caller. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { e->rule.action = newaction; e->rule.file_count = newfield_count; write_unlock(&auditsc_lock); return 0; } } write_unlock(&auditsc_lock); return -EFAULT; /* No matching rule */ }
如果使用RCU,修改代码应当为;
static inline int audit_upd_rule(struct audit_rule *rule, struct list_head *list, __u32 newaction, __u32 newfield_count) { struct audit_entry *e; struct audit_newentry *ne; list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { ne = kmalloc(sizeof(*entry), GFP_ATOMIC); if (ne == NULL) return -ENOMEM; audit_copy_rule(&ne->rule, &e->rule); ne->rule.action = newaction; ne->rule.file_count = newfield_count; list_replace_rcu(e, ne); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ }
3.修改操作立即可见
前面两种情况,读者能够容忍修改可以在一段时间后看到,也就说读者在修改后某一时间段内,仍然看到的是原来的数据。在很多情况下,读者不能容忍看到旧的数据,这种情况下,需要使用一些新措施,如System V IPC,它在每一个链表条目中增加了一个deleted字段,标记该字段是否删除,如果删除了,就设置为真,否则设置为假,当代码在遍历链表时,核对每一个条目的deleted字段,如果为真,就认为它是不存在的。
还是以系统调用审计代码为例,如果它不能容忍旧数据,那么,读端代码应该修改为:
static enum audit_state audit_filter_task(struct task_struct *tsk) { struct audit_entry *e; enum audit_state state; rcu_read_lock(); list_for_each_entry_rcu(e, &audit_tsklist, list) { if (audit_filter_rules(tsk, &e->rule, NULL, &state)) { spin_lock(&e->lock); if (e->deleted) { spin_unlock(&e->lock); rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; } rcu_read_unlock(); return state; } } rcu_read_unlock(); return AUDIT_BUILD_CONTEXT; }
注意,对于这种情况,每一个链表条目都需要一个spinlock保护,因为删除操作将修改条目的deleted标志。此外,该函数如果搜索到条目,返回时应当保持该条目的锁,因为只有这样,才能看到新的修改的数据,否则,仍然可能看到就的数据。
写端的删除操作将变成:
static inline int audit_del_rule(struct audit_rule *rule, struct list_head *list) { struct audit_entry *e; /* Do not use the _rcu iterator here, since this is the only * deletion routine. */ list_for_each_entry(e, list, list) { if (!audit_compare_rule(rule, &e->rule)) { spin_lock(&e->lock); list_del_rcu(&e->list); e->deleted = 1; spin_unlock(&e->lock); call_rcu(&e->rcu, audit_free_rule, e); return 0; } } return -EFAULT; /* No matching rule */ }
删除条目时,需要标记该条目为已删除。这样读者就可以通过该标志立即得知条目是否已经删除。
六、小结RCU是2.6内核引入的新的锁机制,在绝大部分为读而只有极少部分为写的情况下,它是非常高效的,因此在路由表维护、系统调用审计、SELinux的AVC、dcache和IPC等代码部分中,使用它来取代rwlock来获得更高的性能。但是,它也有缺点,延后的删除或释放将占用一些内存,尤其是对嵌入式系统,这可能是非常昂贵的内存开销。此外,写者的开销比较大,尤其是对于那些无法容忍旧数据的情况以及不只一个写者的情况,写者需要spinlock或其他的锁机制来与其他写者同步。
在作者先前的两篇文章"Linux 实时技术与典型实现分析, 第 1 部分: 介绍"和"Linux 实时技术与典型实现分析, 第 2 部分: Ingo Molnar 的实时补丁"中,Ingo Molnar的实时实现要求RCU读端临界区可抢占,而RCU的实现的前提是读端临界区不可抢占,因此如何解决这一矛盾但同时不损害RCU的性能是RCU未来的一大挑战。
参考资料[1] Linux RCU实现者之一Paul E. McKenney的RCU资源链接,。
[2] Paul E. McKenney的博士论文,"Exploiting Deferred Destruction: An Analysis of Read-Copy Update Techniques in Operating System Kernels",。
[3] Paul E. McKenney's paper in Ottawa Linux Summit 2002, Read-Copy Update,。
[4] Linux Journal在2003年10月对RCU的简介, Kernel Korner - Using RCU in the Linux 2.5 Kernel,。
[5] Scaling dcache with RCU, 。
[6] Patch: Real-Time Preemption and RCU,。
[7] Using Read-Copy Update Techniques for System V IPC in the Linux 2.5 Kernel, 。
[8] Linux 2.6.12 kernel source。
[9] Linux kernel documentation, Documentation/RCU/*。