我使用的nginx是1.2.1的源码安装的,因为nginx自带的fail次数检测并不能真正地实现停止对后端app的转发,因此考虑用nginx_upstream_check_module模块来做后端web的健康监测。
下载nginx的模块https://github.com/yaoweibin/nginx_upstream_check_module
cd /usr/local
tar zxvf nginx-1.2.1.tar.gz
unzip yaoweibin-nginx_upstream_check_module-v0.1.6-17-gdfee401.zip
cd nginx-1.2.1
patch -p1 < /usr/local/yaoweibin-nginx_upstream_check_module-dfee401/check_1.2.1+.patch
(如果你的nginx版本不是1.2.1以上的,请用patch -p1 < /usr/local/yaoweibin-nginx_upstream_check_module-dfee401/check.patch)
(nginx用户自己创建吧)
./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_realip_module --with-http_addition_module --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gzip_static_module --with-http_random_index_module --with-http_secure_link_module --with-http_stub_status_module --with-mail --with-mail_ssl_module --with-file-aio --with-ipv6 --add-module=/usr/local/yaoweibin-nginx_upstream_check_module-dfee401/
make
make install
编辑nginx的配置文件,在http里面增加你的check健康
upstream backend
{
ip_hash;
server 192.168.64.98:58580;
check interval=1000 rise=2 fall=2 timeout=1000;
server 192.168.64.140:58580;
check interval=1500 rise=2 fall=2 timeout=1000;
#server 192.168.64.182:9090 max_fails=30 fail_timeout=30s;
#server 192.168.64.99:58590 max_fails=30 fail_timeout=30s down;
}
interval检测间隔时间,单位为毫秒,rsie请求2次正常的话,标记此realserver的状态为up,fall表示请求2次都失败的情况下,标记此realserver的状态为down,timeout为超时时间,单位为毫秒。
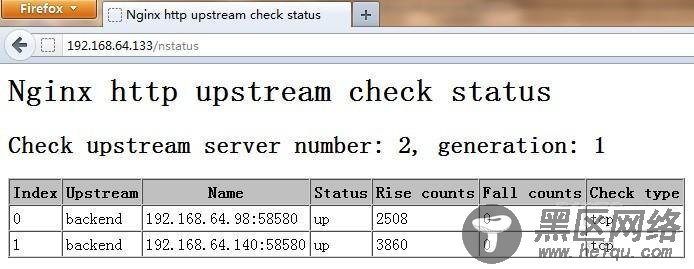
在server段里面可以加入查看realserver状态的页面
location /nstatus {
check_status;
access_log off;
#allow SOME.IP.ADD.RESS;
#deny all;
}
打开nstatus就可以看到web的健康状况