回到图23,可发现有“17小时前”,由此可见,这里采集数字17就可以了。采集规则为“<span class=”bh”>[内容]小时前</span>”。这里不需要使用过滤规则。填写后,如图30所示,
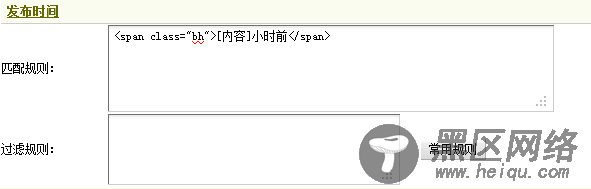
图30-文章发布时间的采集规则
2.1.5 获取图片集合以及图集内容的采集规则这个部分是编写采集规则的重点,也是难点。需要特别注意。
图片集合:如果把采集的匹配规则填写在这里的话,系统就会把所采集到的图片,以图集的形式保存起来,注意这里只采集图片。
图集内容:在显示图集的时候,所需显示的说明性文字或者图片。
具体操作步骤:
(a)在打开的内容页面的源代码中,找到内容的开始部分“一些壁纸”,如图31所示,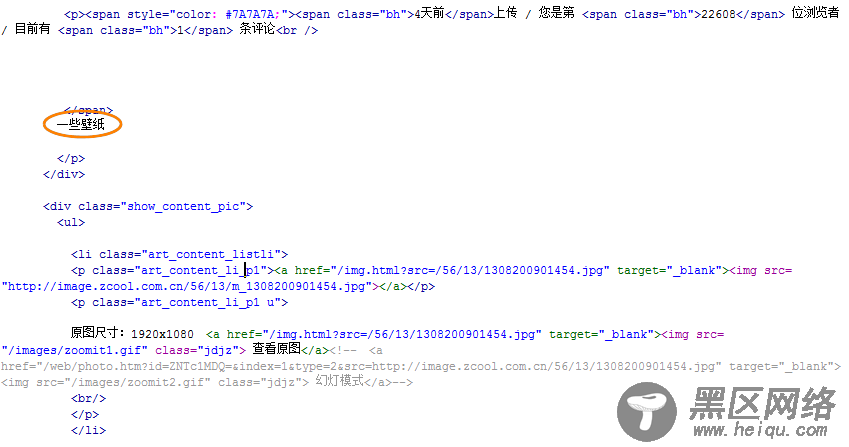
图31-内容的开始部分
分析一下这个源代码可知,以下两点:
(1)“一些壁纸”是这个图集的内容,因此可以把“条评论<br/>”作为匹配图集内容的开始部分。但是这样采集到的内容会包含有</span>,应该在过滤规则中使用“{dede:trim replace=""}</span>{/dede:trim}”过滤掉。
(2)“<div class=”show_content_pic”><ul>”可作为匹配图片集合的开始部分,而且每一个图片及其相关信息都是在“<li class=”art_content_listli”>”和”</li>”之间的。注意到这段代码中有两个地方都出现了<img>,通过对比原文可发现,”<img src=http://www.dede58.com/”/images/zoomit1.gif” class=”jdjz”>”是一个图标的源代码,这里是不应该被采集到的。为了过滤掉这个图标,需要在匹配规则中填写“{dede:trim replace=""}<p class="art_content_li_p1 u">(.*)</p>{/dede:trim}”。
填写后,如(图32)所示,
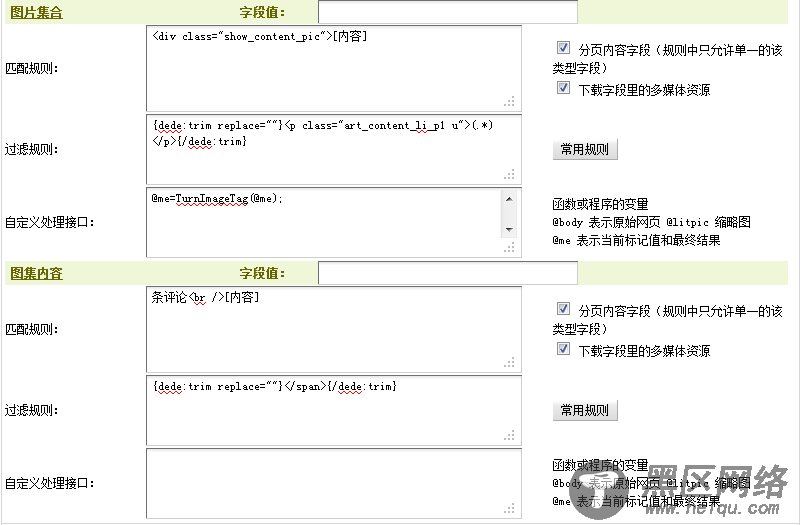
图32-开始部分的匹配规则及其过滤规则
(b)找到图集内容的结束部分,因为涉及到分页部分,所以应该选取分页结束的位置,如图33所示,

图33-图集内容的结束部分
很明显,这里应选取“<li style="text-align:center;"><script type="text/javascript”>”作为图片集合和图集内容的结束部分。填写完成后,如(图34)所示,
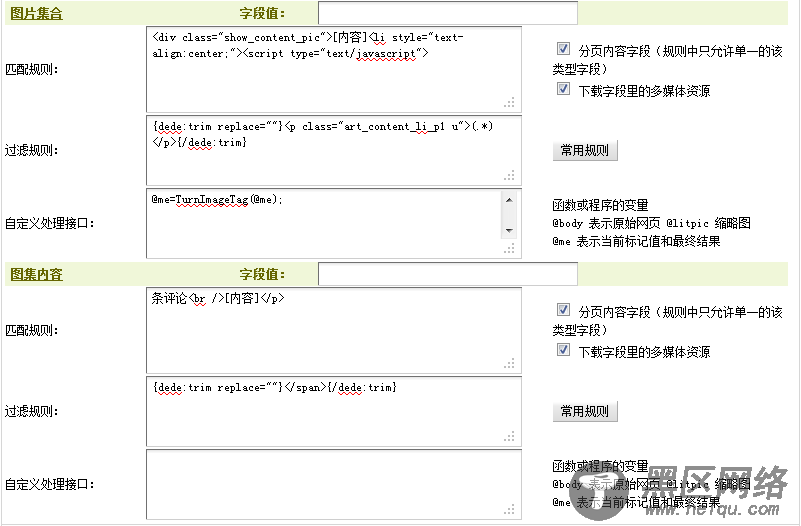
图34-结束部分的匹配规则及其过滤规则
到这里,“新增采集节点:第二步设置内容字段获取规则”,就设置完成了。来看一下整个配置页面,如(图35)所示,

图35-设置后的新增采集节点:第二步设置内容字段获取规则
检查无误后,单击“保存并测试”。如果之前设置正确,单击后,将会进入“新增采集节点:测试内容字段设置”页面并看到相应的文章内容。如(图36)所示,
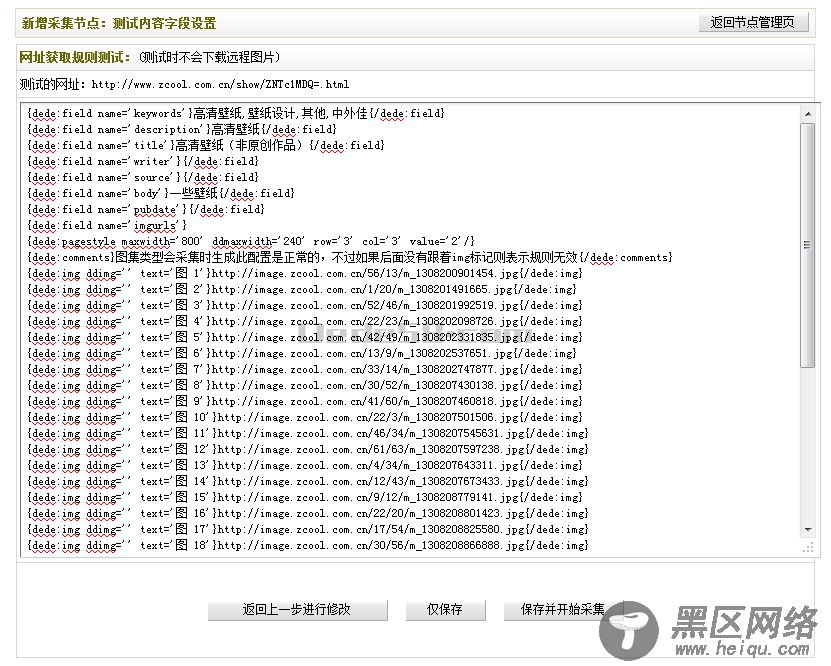
图36-新增采集节点:测试内容字段设置
确定正确无误后,如果单击“仅保存”,系统将会提示“成功保存配置“并返回”采集节点管理“界面;如果单击“保存并开始采集“,将会进入”采集指定节点“界面。否则,请单击“返回上一步进行修改”。
关于第二节的介绍就到这里。下面进入第三节。。。