
前几天在看 2018 云栖大会,来自中科院计算所的陈世敏研究员在“数据库内核专场”做了一场《NVM在数据库领域的研究和探索 》的报告演讲。在30分钟的演讲中,其中有近10页PPT的内容和B+Tree这种索引有关。
例如其中的两页
为此,将自己对索引相关的理解梳理如下:
1.什么是索引?索引是磁盘上组织数据记录的一种数据结构,它用来优化某类数据查询的操作。索引使得我们能够有效地查询满足索引的查询码(搜索码)字段上的查询条件的那些记录。可以在一个给定的数据记录集合上创建多个索引,每个索引有不同的查询码(搜索码)。
2.主键 与 聚集索引主键是一种约束,主要用来保证数据的完整性,而聚集索引是一种文件(数据记录)的组织形式,索引的目的是查询优化,两者是不同的概念。
但两者并非完全没有联系,比如SQL SERVER默认是在主键上建立聚集索引的。在大多数情况下,默认建立的聚集索引是不起作用的,还是需要结合实际的业务场景来考虑,特别是在选择自增ID或GUID这种主键的情况。
创建主键,不可以再允许为Null值的列上创建,并且既有的数据记录中不可以有重复值,否则报错。聚集索引没有限制建立聚集索引的列一定必须 not null ,并且数据即可以唯一,也可以不唯一。
3.聚集索引 与 非聚集索引聚集索引叶子层:具体的数据,按照聚集键顺序存储
非聚集索引叶子层:指针,指针有2类数据 RID或者是聚集键。
RID(堆表) RID【文件号:页号:槽号 8 bytes — 文件号(4 bytes):页号(2 bytes):槽号(2 bytes)】
聚集键(聚集表) 聚集键(聚集索引主键)
聚集键与非聚集索引有紧密的依赖关系,聚集键在每个非聚集索引叶子层都保存,慎重选择聚集键。
非聚集索引是第二索引, 对提高查询性能至关重要。
4.什么是书签查找非聚集索引不包含查询需要的列,需要通过书签查找来获取所查询列信息。常见的书签查找有两种:一个是键查找(key lookup,聚簇索引的表),还有一个就是RID查找(RID lookup,堆表)。
使用覆盖索引,让非聚集索引包含查询列,从而避免书签查找。但是非聚集索引最大键列数为16,最大索引键大小为900字节,所以覆盖索引还是有限制的,此时可以考虑 使用include属性来包含非键列。
5.二叉树 与 B-树索引的存放为什么不用大家熟悉的二叉树,从数据结构上来讲 二叉树的查找速度最快和比较次数最少。主要考虑的因此是I/O的次数。查找时,在某非叶子节点决定下一步向左(小于)还是向右(大于或等于)的判断比较时,都需要将节点数据I/O到内存中,即需要发生一次I/O。所以最坏的情况下磁盘IO的次数有数的高度来决定(最坏的情况可以理解为想要查找的数在叶子节点上)。所以减少磁盘I/O的次数就必须要压缩树的高度。从数据库的基本原理,我们就知道,页I/O(从磁盘输入到主存及从主存输出到磁盘)的代价代表了典型的数据库操作代价,因此需要十分小心地优化数据库系统来减少这个代价。而B-树正好瞒住了这个要求。在B-树中,每一个非叶子节点可以容纳很多节点指针,从而树的高度在实际中很少超过3或4.一个平衡数的高度是从根到叶子的路径长度。实际上,根通常是存放在缓冲池中,因为它要被频繁的访问,所以一个高度为3的树,其实只需要3次I/O。
非叶子节点的平均孩子树称为树的扇出(fan-out)。如果每一个非叶子节点有n个孩子,则高度为h的树有nh叶子页。实际 上 ,节点并没有相同数量的孩子,但是用n的平均数值F,我们可以获得叶子页数量的很好的近似结果Fh。在实际情况中,F至少为100,这意味着高度为4的树包含1亿个叶子页。因此,可以只用4次I/O就从有1亿个叶子页的文件中搜索到想要的页。与之相似,采用二分法搜索同样的文件则需要花费log2100000000 (超过25)次I/0
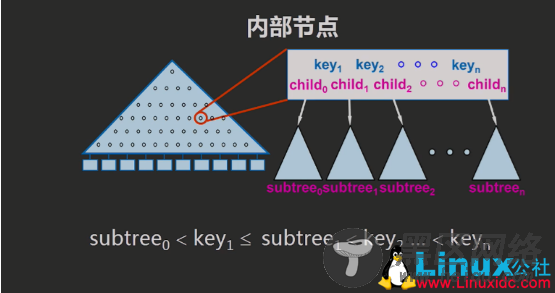
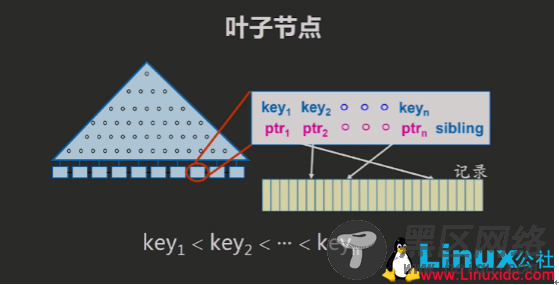
6.B-树 与 B+树与B-Tree相比,B+Tree有以下不同点:
每个节点的指针上限为2d而不是2d+1。
B+树是一种保证在一颗给定树中从根到叶所有路径都等长的索引结构,即,这种树的高度总是平衡的。
内节点不存储data,只存储key。 B+Tree的搜索与B-Tree也基本相同,区别是B+Tree只有达到叶子结点才命中(B-Tree可以在非叶子结点命中)。