
今天学习下Oracle中索引组织表,通过这篇文章,你可了解到,什么是索引组织表?什么情况下可以使用索引组织?索引组织表的优点?索引组织表的弊端?
一:什么时候索引组织表(IOT)
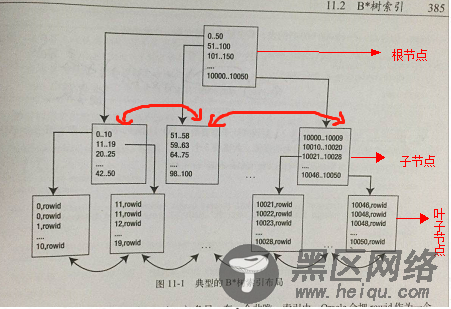
索引组织表(index organized table): 索引组织表以B*树结构存储,我们知道Oracle默认的表是是堆表,堆表是以一种无组织的方式存储的(只要有可用的空间,就可以放数据),而IOT与之不同,IOT中的数据按着主键的顺序存储和排序的,对于应用来说,IOT表现得和常规的堆表并无区别,需要只用sql来正确的来访问IOT,简单的概述起来:索引组织表----》索引就是数据,数据就是索引,因为数据就是按着B*树结构存储的。如下图是一个典型的B*tree索引的结构(针对Oracle b*tree索引的理解请参考我的另一篇文章 )。
而我们今天探讨的索引组织表也是按着这个结构存储数据的,它与B*tree索引的区别是:B*tree索引叶子节点存储是索引键值+rowid;而索引组织表的叶子节点存储的是整行数据,这很类似于mysql的innodb引擎的表。需要注意的是IOT对于主键的设置格外严格,要求创建表的时候就必须指定明确的主键列,因为IOT中的数据是按着主键的顺序存储和排序的
二;索引组织表的优点
1)首先显而易见的是索引组织表是可以节约空间的,因为索引和表合二为一,
2)还有就是根据主键进行唯一扫描或者范围扫描的时候由于索引的排列顺序这些列是按索引排列好的,而且比一般索引少一次ROWID回表的操作,那么速度会更快,
3)其次如果根据数据特点比如一个身份证号ID,一个银行卡号,显然一个身份证号ID可以有多个银行卡号,如果我们建立索引组织表结构为(身份证号ID和银行卡号),显然如果在查询的时候使用ID=** 那么这种情况下,索引组织表的优势就出来了,首先他少一次ROWID回表操作,其次索引组织表的排列是有序的,那么同一个身份证的ID的的卡号信息一定存储在临近的块中,这实际也是第二点的一个列子。
4)在堆组织表中,两行数据在同一个数据库块上的可能性几乎为0,而iot表根据主键排序后的顺序进行排列,所以在按着时间范围或者按着主键范围查询的数据在同一个块上或者相邻的块上,所以查询出来这些数据需要的逻辑io 和物理io都会减少。
5)提高缓冲区缓存效率,因为给定查询在缓存中需要的块更少,·减少缓冲区缓存访问,这会改善可扩缩性。
三:索引组织表的弊端以及适用场景:
索引组织表(IOT)不仅可以存储数据,还可以存储为表建立的索引。索引组织表的数据是根据主键排序后的顺序进行排列的,这样就提高了访问的速度。但是由于每次写入和更新后都要重新进行重新排序,导致插入和更新性能降低,所以个人认为在oltp系统中,不太适合使用IOT表,
IOT对信息获取、空间系统和OLAP应用最为有用,如果经常在一个主键或唯一键上使用between查询,如果数据有序地物理存储,就能提升这些查询的性能,
四:说下Oracle索引组织表的溢出段(overflow段)
1)overflow段存在的意义
为了让索引叶子块(包含具体索引数据的块)能够高效地存储数据,索引一般在一个列子集上,通常索引块上的行数比堆表块上的行数多出几倍。索引指望着每块能得到多行,否则,Oracle会花费大量的时间来维护索引,因为每个insert或update都可能导致索引块分解。
创建IOT时,overflow子句允许你建立另一个段(就相当于让IOT成为了一个多段对象,就像有一个CLOB列一样)如果IOT的行数据变得太大,就可以溢出到这个段中。读取数据的时候,Oracle将读取行的"首部",找到行余下部分的指针,然后读取这些部分。
再就是因为所有数据都放入索引,所以当表的数据量很大时,会降低索引组织表的查询性能。此时设置溢出段将主键和溢出数据分开来存储以提高效率。注意长期都是SELECT * FROM 那么溢出段也就没有用处;
2)overflow段实现的方式;PCTTHRESHOLD和INCLUDING 两种
PCTTHRESHOLD n :制定一个数据块的百分比,当行中的数据量超过块的这个百分比的时候,行中余下的列将存储在溢出段,例如PCTTHRESHOLD是10%,而块的大小是8kb,所以长度大于800字节的行就会把其中一部分列值存储在别处,而不能在索引块上存储。
INCLUDING column_name :行中从第一列直到INCLUDING字句所指定列(包括这个列在内)都放入索引块,之后的列都放到溢出段
3)关于overflow段实现的方式的选择标准
1.如果你的应用中总是(或者几乎总是)使用表的前4列,而很少访问后5列,使用INCLUDING会更合适;