
Spark集群处理能力不足需要扩容,如何在现有spark集群中新增新节点?本文以一个实例介绍如何给Spark集群新增一个节点。
1. 集群环境现有Spark集群包括3台机器,用户名都是cdahdp,主目录/home/ap/cdahdp,配置是2C8G虚拟机,集群基于yarn架构。
Master:128.196.54.112/W118PC01VM01
Slave1:128.196.54.113/W118PC02VM01
Slave2:128.196.54.114/W118PC03VM01
相关软件版本:jdk1.7、scala2.10.4、Hadoop2.6.0、spark1.1
现在需要新增一个节点:128.196.54.115/W118PC04VM01,2C8G
首先停止当前集群:停止spark,停止hdfs和yarn。
2. 新节点要求
(1)新节点需要增加用户cdahdp,主目录/home/ap/cdahdp。与集群现有机器一致。
(2)修改所有节点的/etc/hosts文件,更新新节点的ip hostname配置。
(3)配置ssh,使新节点与集群中各节点能够无密码互相ssh登录。
(4)在新节点上安装jdk、scala、hadoop和spark。其版本,安装目录,环境变量设置与集群中现有节点保持一致。比如可以直接从集群节点赋值。
3. 配置文件修改(1)修改$HADOOP_HOME/etc/hadoop/slaves文件,增加新节点作为slave节点。
(2)修改$SPARK_HOME/conf/slaves文件,增加新节点作为slave节点。
(3)格式化新节点的namenode:
cd $HADOOP_HOME/bin
./hdfs namenode -format
4. 启动新集群启动hdfs,yarn,以及spark。
cd $HADOOP_HOME/sbin
./start-dfs.sh && ./start-yarn.sh
cd $SPARK_HOME/sbin
./start-all.sh
扩容以前:
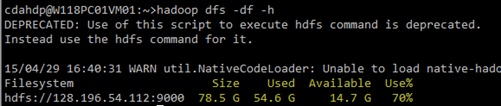
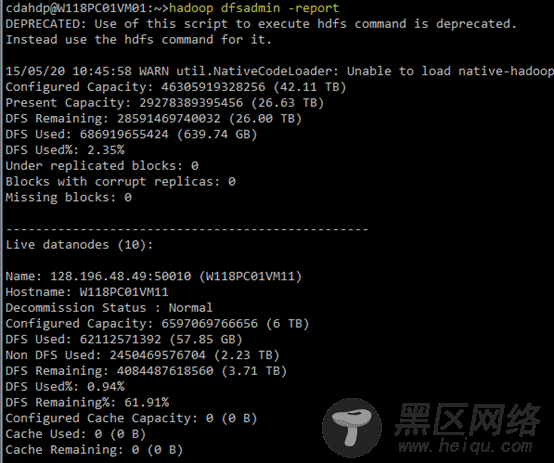
扩容以后:

(1)查看HDFS集群的基本信息:执行hadoop dfsadmin -report
(2)负载均衡:在$HADOOP_HOME/sbin/下执行start-balancer.sh
说明:balancer操作是一个较慢的过程,所以在后台执行。balance过程中,数据在各节点之间迁移的速度默认是1M/s。
负载均衡之前:
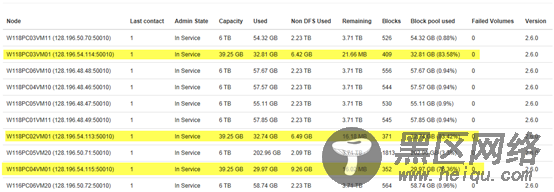
执行负载均衡:

负载均衡之后:
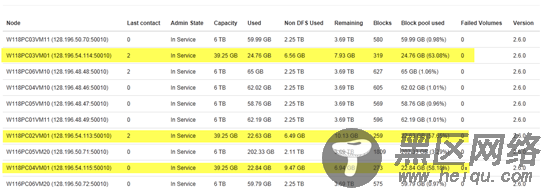
至此,在spark集群增加新节点完毕。
--------------------------------------分割线 --------------------------------------
CentOS 6.2(64位)下安装Spark0.8.0详细记录
Spark简介及其在Ubuntu下的安装使用
--------------------------------------分割线 --------------------------------------