
按照多个属性的数据分片
当只需要通过主键来访问数据的时候,一致性hash的数据放置策略很有效,但是当需要按照多个属性来查询的时候事情就会复杂得多。一种简单的做法(MongoDB使用的)是用主键来分布数据而不考虑其他属性。这样做的结果是依据主键的查询可以被路由到接个合适的节点上,但是对其他查询的处理就要遍历集群的所有节点。查询效率的不均衡造成下面的问题:
有一个数据集,其中的每条数据都有若干属性和相应的值。是否有一种数据分布策略能够使得限定了任意多个属性的查询会被交予尽量少的几个节点执行?
HyperDex数据库提供了一种解决方案。基本思想是把每个属性视作多维空间中的一个轴,将空间中的区域映射到物理节点上。一次查询会被对应到一个由空间中多个相邻区域组成的超平面,所以只有这些区域与该查询有关。让我们看看参考资料中的一个例子:
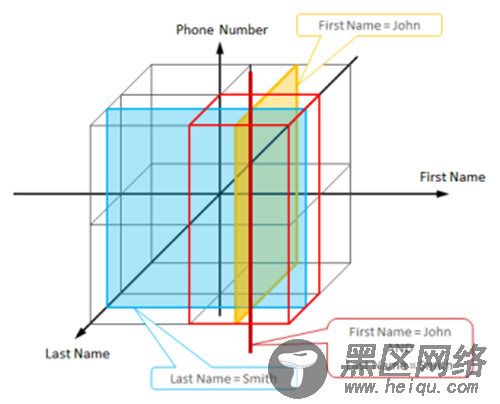
每一条数据都是一条用户信息,有三个属性First Name 、Last Name 和Phone Number。这些属性被视作一个三维空间,可行的数据分布策略是将每个象限映射到一个物理节点。像“First Name = John”这样的查询对应到一个贯穿4个象限的平面,也即只有4个节点会参与处理此次查询。有两个属性限制的查询对应于一条贯穿两个象限的直线,如上图所示,因此只有2个节点会参与处理。
这个方法的问题是空间象限会呈属性数的指数函数增长。结果就会是,只有几个属性限制的查询会投射到许多个空间区域,也即许多台服务器。将一个属性较多的数据项拆分成几个属性相对较少的子项,并将每个子项都映射到一个独立的子空间,而不是将整条数据映射到一个多维空间,这样可以一定程度上缓解这个问题:
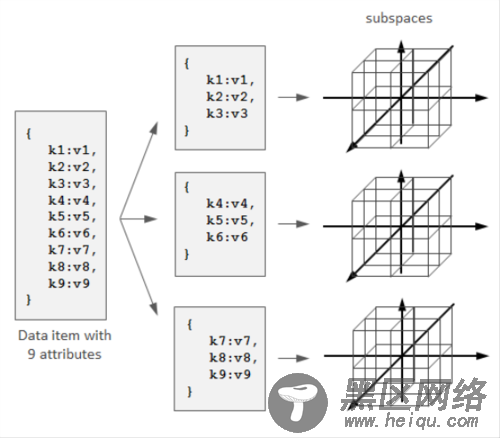
这样能够提供更好的查询到节点的映射,但是增加了集群协调的复杂度,因为这种情况下一条数据会散布在多个独立的子空间,而每个子空间都对应各自的若干个物理节点,数据更新时就必须考虑事务问题。
钝化副本有的应用有很强的随机读取要求,这就需要把所有数据放在内存里。在这种情况下,将数据分片并把每个分片主从复制通常需要两倍以上的内存,因为每个数据都要在主节点和从节点上各有一份。为了在主节点失效的时候起到代替作用,从节点上的内存大小应该和主节点一样。如果系统能够容忍节点失效的时候出现短暂中断或性能下降,也可以不要分片。
下面的图描绘了4个节点上的16个分片,每个分片都有一份在内存里,副本存在硬盘上:
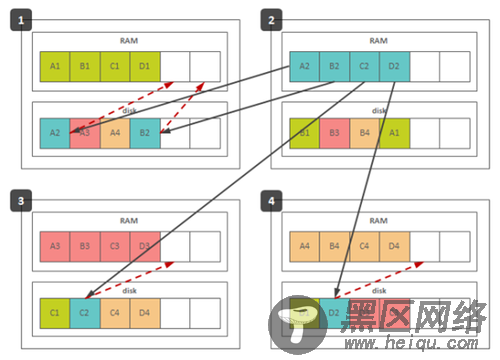
灰色箭头突出了节点2上的分片复制。其他节点上的分片也是同样复制的。红色箭头描绘了在节点2失效的情况下副本怎样加载进内存。集群内副本的均匀分布使得只需要预留很少的内存就可以存放节点失效情况下激活的副本。在上面的图里,集群只预留了1/3的内存就可以承受单个节点的失效。特别要指出的是副本的激活(从硬盘加载入内存)会花费一些时间,这会造成短时间的性能下降或者正在恢复中的那部分数据服务中断。
系统协调在这部分我们将讨论与系统协调相关的两种技术。分布式协调是一个比较大的领域,数十年以来有很多人对此进行了深入的研究。这篇文章里只涉及两种已经投入实用的技术。关于分布式锁,consensus协议以及其他一些基础技术的内容可以在很多书或者网络资源中找到。
故障检测故障检测是任何一个拥有容错性的分布式系统的基本功能。实际上所有的故障检测协议都基于心跳通讯机制,原理很简单,被监控的组件定期发送心跳信息给监控进程(或者由监控进程轮询被监控组件),如果有一段时间没有收到心跳信息就被认为失效了。除此之外,真正的分布式系统还要有另外一些功能要求:
自适应。故障检测应该能够应对暂时的网络故障和延迟,以及集群拓扑、负载和带宽的变化。但这有很大难度,因为没有办法去分辨一个长时间没有响应的进程到底是不是真的失效了,因此,故障检测需要权衡故障识别时间(花多长时间才能识别一个真正的故障,也即一个进程失去响应多久之后会被认为是失效)和虚假警报率之间的轻重。这个权衡因子应该能够动态自动调整。
灵活性。乍看上去,故障检测只需要输出一个表明被监控进程是否处于工作状态的布尔值,但在实际应用中这是不够的。我们来看参考资料中的一个类似MapReduce的例子。有一个由一个主节点和若干工作节点组成的分布式应用,主节点维护一个作业列表,并将列表中的作业分配给工作节点。主节点能够区分不同程度的失败。如果主节点怀疑某个工作节点挂了,他就不会再给这个节点分配作业。其次,随着时间推移,如果没有收到该节点的心跳信息,主节点就会把运行在这个节点上的作业重新分配给别的节点。最后,主节点确认这个节点已经失效,并释放所有相关资源。
可扩展性和健壮性。失败检测作为一个系统功能应该能够随着系统的扩大而扩展。他应该是健壮和一致的,也即,即使在发生通讯故障的情况下,系统中的所有节点都应该有一个一致的看法(即所有节点都应该知道哪些节点是不可用的,那些节点是可用的,各节点对此的认知不能发生冲突,不能出现一部分节点知道某节点A不可用,而另一部分节点不知道的情况)
所谓的累计失效检测器可以解决前两个问题,Cassandra对它进行了一些修改并应用在产品中。其基本工作流程如下:
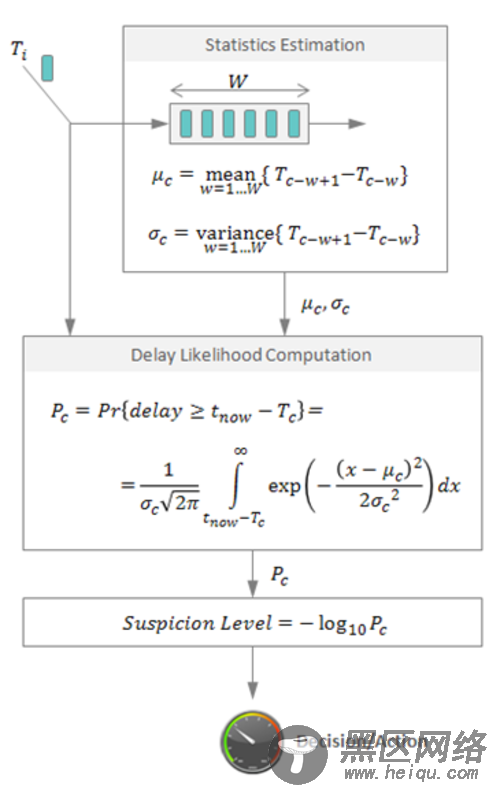
对于每一个被监控资源,检测器记录心跳信息到达时间Ti。
计算在统计预测范围内的到达时间的均值和方差。
假定到达时间的分布已知(下图包括一个正态分布的公式),我们可以计算心跳延迟(当前时间t_now和上一次到达时间Tc之间的差值) 的概率,用这个概率来判断是否发生故障。可以使用对数函数来调整它以提高可用性。在这种情况下,输出1意味着判断错误(认为节点失效)的概率是10%,2意味着1%,以此类推。
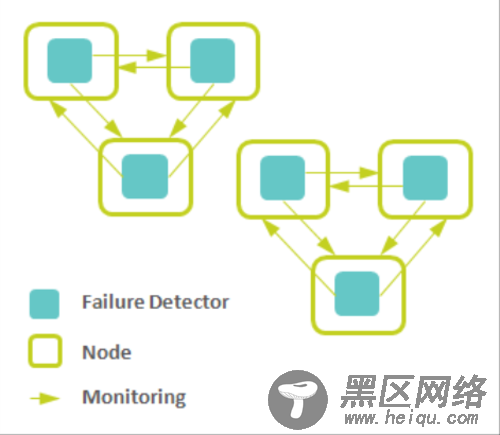
根据重要程度不同来分层次组织监控区,各区域之间通过谣言传播协议或者中央容错库同步,这样可以满足扩展性的要求,又可以防止心跳信息在网络中泛滥。如下图所示(6个故障检测器组成了两个区域,互相之间通过谣言传播协议或者像ZooKeeper这样的健壮性库来联系):
协调者竞选是用于强一致性数据库的一个重要技术。首先,它可以组织主从结构的系统中主节点的故障恢复。其次,在网络隔离的情况下,它可以断开处于少数的那部分节点,以避免写冲突。
Bully 算法是一种相对简单的协调者竞选算法。MongoDB 用了这个算法来决定副本集中主要的那一个。Bully 算法的主要思想是集群的每个成员都可以声明它是协调者并通知其他节点。别的节点可以选择接受这个声称或是拒绝并进入协调者竞争。被其他所有节点接受的节点才能成为协调者。节点按照一些属性来判断谁应该胜出。这个属性可以是一个静态ID,也可以是更新的度量像最近一次事务ID(最新的节点会胜出)。
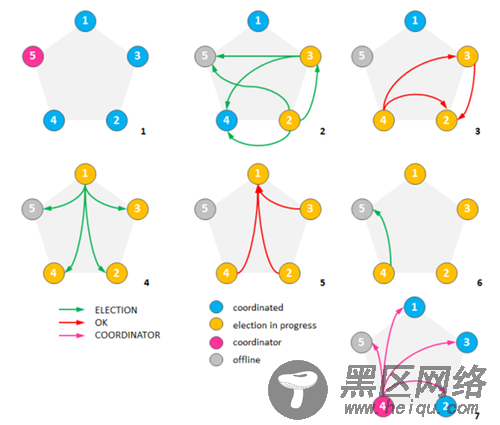
下图的例子展示了bully算法的执行过程。使用静态ID作为度量,ID值更大的节点会胜出:
最初集群有5个节点,节点5是一个公认的协调者。
假设节点5挂了,并且节点2和节点3同时发现了这一情况。两个节点开始竞选并发送竞选消息给ID更大的节点。
节点4淘汰了节点2和3,节点3淘汰了节点2。
这时候节点1察觉了节点5失效并向所有ID更大的节点发送了竞选信息。
节点2、3和4都淘汰了节点1。
节点4发送竞选信息给节点5。
节点5没有响应,所以节点4宣布自己当选并向其他节点通告了这一消息。
协调者竞选过程会统计参与的节点数目并确保集群中至少一半的节点参与了竞选。这确保了在网络隔离的情况下只有一部分节点能选出协调者(假设网络中网络会被分割成多块区域,之间互不联通,协调者竞选的结果必然会在节点数相对比较多的那个区域中选出协调者,当然前提是那个区域中的可用节点多于集群原有节点数的半数。如果集群被隔离成几个区块,而没有一个区块的节点数多于原有节点总数的一半,那就无法选举出协调者,当然这样的情况下也别指望集群能够继续提供服务了)。