
Hadoop已被公认为大数据分析领域无可争辩的王者,它专注与批处理。这种模型对许多情形(比如:为网页建立索引)已经足够,但还存在其他一些使用模型,它们需要来自高度动态的来源的实时信息。为了解决这个问题,就得借助Twitter推出得Storm。Storm不处理静态数据,但它处理预计会连续的流数据。考虑到Twitter用户每天生成1.4亿条推文,那么就很容易看到此技术的巨大用途。
但Storm不只是一个传统的大数据分析系统:它是复杂事件处理(CEP)系统的一个示例。CEP系统通常分类为计算和面向检测,其中每个系统都是通过用户定义的算法在Storm中实现。举例而言,CEP可用于识别事件洪流中有意义的事件,然后实时的处理这些事件。
2.为什么Hadoop不适合实时计算这里说的不适合,是一个相对的概念。如果业务对时延要求较低,那么这个 问题就不存在了;但事实上企业中的有些业务要求是对时延有高要求的。下面我 就来说说:
2.1时延Storm 的网络直传与内存计算,其时延必然比 Hadoop 的 HDFS 传输低得多;当计算模型比较适合流式时,Storm 的流试处理,省去了批处理的收集数据的时 间;因为 Storm 是服务型的作业,也省去了作业调度的时延。所以从时延的角 度来看,Storm 要快于 Hadoop,因而 Storm 更适合做实时流水数据处理。下面用一个业务场景来描述这个时延问题。
2.1.1业务场景几千个日志生产方产生日志文件,需要对这些日志文件进行一些 ETL 操作存 入数据库。
我分别用 Hadoop 和 Storm 来分析下这个业务场景。假设我们用 Hadoop 来 处理这个业务流程,则需要先存入 HDFS,按每一分钟(达不到秒级别,分钟是最小纬度)切一个文件的粒度来计算。这个粒度已经极端的细了,再小的话 HDFS 上会一堆小文件。接着 Hadoop 开始计算时,一分钟已经过去了,然后再开始 调度任务又花了一分钟,然后作业运行起来,假设集群比较大,几秒钟就计算完 成了,然后写数据库假设也花了很少时间(理想状况下);这样,从数据产生到 最后可以使用已经过去了至少两分多钟。
而我们来看看流式计算则是数据产生时,则有一个程序一直监控日志的产生, 产生一行就通过一个传输系统发给流式计算系统,然后流式计算系统直接处理, 处理完之后直接写入数据库,每条数据从产生到写入数据库,在资源充足(集群 较大)时可以在毫秒级别完成。
2.1.2吞吐在吞吐量方面,Hadoop 却是比 Storm 有优势;由于 Hadoop 是一个批处理计算,相比 Storm 的流式处理计算,Hadoop 的吞吐量高于 Storm。
2.2应用领域Hadoop 是基于 MapReduce 模型的,处理海量数据的离线分析工具,而 Storm是分布式的,实时数据流分析工具,数据是源源不断产生的,比如:Twitter 的 Timeline。另外,M/R 模型在实时领域很难有所发挥,它自身的设计特点决定了 数据源必须是静态的。
2.3硬件Hadoop 是磁盘级计算,进行计算时,数据在磁盘上,需要读写磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快 N 个 数量级。根据行业结论,磁盘访问延迟约为内存访问延迟的 7.5w 倍,所以从这 个方面也可以看出,Storm 从速度上更快。
3.详细分析在分析之前,我们先看看两种计算框架的模型,首先我们看下MapReduce的模型,以WordCount为例,如下图所示:
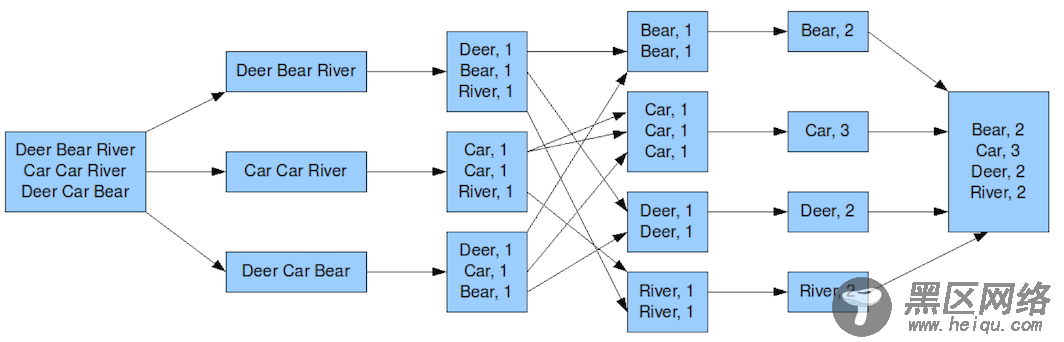
阅读过Hadoop源码下的hadoop-mapreduce-project工程中的代码应该对这个流程会熟悉,我这里就不赘述这个流程了。
接着我们在来看下Storm的模型,如下图所示:
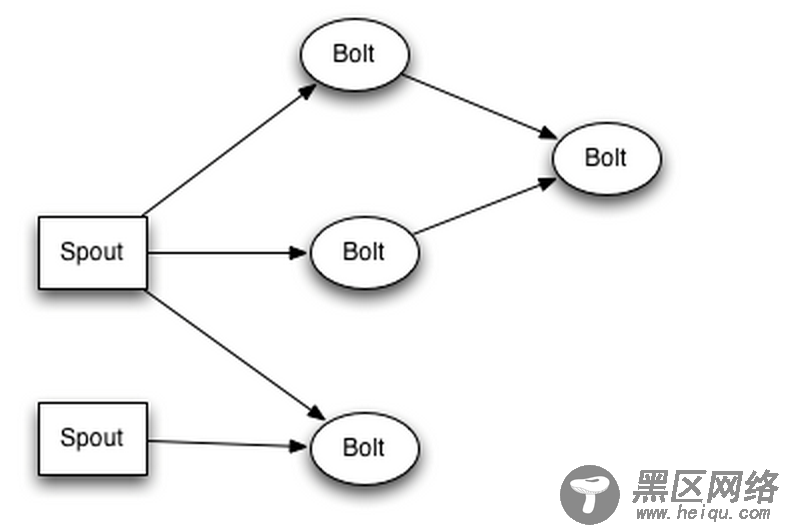
然后下面我们就会涉及到2个指标问题:延时和吞吐。
延时:指数据从产生到运算产生结果的时间。与“速度”息息相关。
吞吐:指系统单位时间处理的数据量。
另外,在资源相同的情况下;一般 Storm 的延时要低于 MapReduce,但是
吞吐吞吐也要低于 MapReduce,下面我描述下流计算和批处理计算的流程。 整个数据处理流程来说大致可以分为三个阶段:
1. 数据采集阶段
2. 数据计算(涉及计算中的中间存储)
3. 数据结果展现(反馈)
3.1.1数据采集阶段目前典型的处理策略:数据的产生系统一般出自 Web 日志和解析 DB 的 Log,流计算数据采集是获取的消息队列(如:Kafka,RabbitMQ)等。批处理系统一 般将数据采集到分布式文件系统(如:HDFS),当然也有使用消息队列的。我们 暂且把消息队列和文件系统称为预处理存储。二者在这个阶段的延时和吞吐上没 太大的区别,接下来从这个预处理存储到数据计算阶段有很大的区别。流计算一 般在实时的读取消息队列进入流计算系统(Storm)的数据进行运算,批处理系 统一般回累计大批数据后,批量导入到计算系统(Hadoop),这里就有了延时的 区别。
3.1.2数据计算阶段流计算系统(Storm)的延时主要有以下几个方面: