Hadoop的设计初衷是服务于off-line的数据存储和处理应用。随着这个产品的不断成熟和发展,对于支持on-line应用的需求越来越强烈。例如HBase已经被Facebook和淘宝用到了在线存储应用中。所以Hadoop的on-line化也是一个趋势。目前制约Hadoop作为on-line存储和处理的瓶颈主要是系统的availability。衡量一个分布式系统的主要指标有:reliability, availability & scalability。Hadoop可以做到横向扩展,所以scalability非常好;而用户存在Hadoop里的数据几乎不会丢失,所以reliability也是非常不错的;目前的主要问题在availability,也就是用户向HDFS集群请求数据的时候集群是否能够保证100%提供服务,目前的主要问题体现在HDFS的SPOF(single point of failure),整个HDFS集群的启动/重启时间非常长,配置参数无法动态更改等。这些方面都是apache社区目前工作的重点,本文主要讨论HDFS NameNode的SPOF问题相关的HA机制。
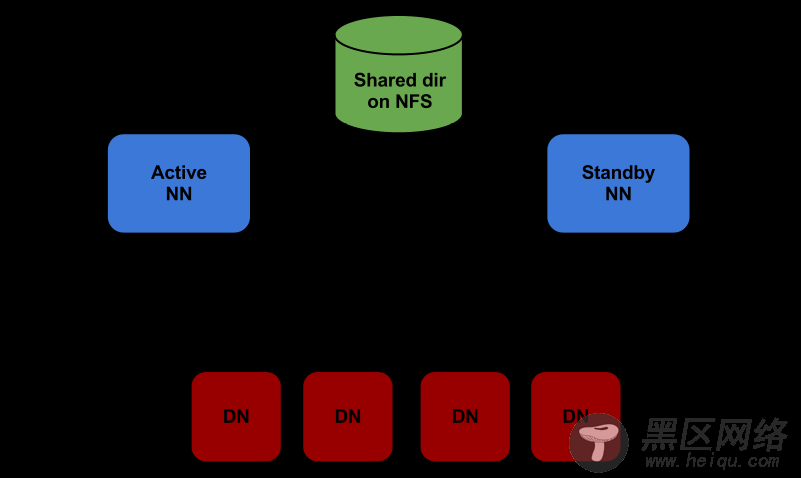
Hadoop目前的trunk中的代码已经merge了原来的ha-branch,所以现在的trunk中的代码已经实现了基本的HA机制的功能。Hadoop PMC的人表示将会在后面的版本中发布这个功能。下面这张图是目前的HDFS HA的实现逻辑。
Right now the HA branch supports HOT-Failover, except that it is manual failover. We are now moving into a phase to implement automatic failover.
Significant enhancements were completed to make HOT Failover work:
- Configuration changes for HA
- Notion of active and standby states were added to the Namenode
- Client-side redirection
- Standby processing editlogs form Active
- Dual block reports to Active and Standby.
这是Hadoop mailing list中关于目前HA现状的阐述。下面首先简单介绍下这5个方面是怎么实现的,后面从源代码的角度分析具体的实现细节。
(1) Configuration changes for HA
在配置文件中会增加关于HA配置的参数,具体参数配置可以参考CDH4 Beta 2 High Availability Guide,这里介绍一些比较重要的参数。
例如dfs.ha.namenodes.[nameservice ID]这个参数表示在[nameservice ID]这个nameservice下的两台NameNode(分别作为Active和Standby模式运行)的主机名。然后针对每一台NN配置其对应的dfs.namenode.rpc-address.[nameservice ID].[name node ID]用来标示每一台NN。
由于目前的两台主机之间的HA机制是通过一个共享存储来存放editlog来实现的。所以需要配置参数dfs.namenode.shared.edits.dir表示共享存储的位置,一般是通过NFS挂载的形式,所以其实这个参数的值就是一个本地文件系统中的目录。
dfs.client.failover.proxy.provider.[nameservice ID]这个参数指定具体的failover proxy provider类,也就是在client端发现原来Active的NameNode变成了Standby模式时(在client发送RPC请求时返回了StandbyException时),该如何去连接当前Active的NameNode。目前的Hadoop里只有一个具体实现策略ConfiguredFailoverProxyProvider,实现方法就是如果client failover时,下次把RPC发送给另外一个NameNode的proxy。
另外就是dfs.ha.fencing.methods参数,指定在Active NameNode切换到Standby模式时,确保切换成功或者进程被杀死。
(2) Notion of active and standby states were added to the Namenode
有两种模式的NameNode,分别是Active和Standby模式。Active模式的NameNode接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat;Standby模式的NameNode同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,使得自己的NameNode中的元数据(Namespcae information + Block locations map)都是和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务。
(3) Client-side redirection
Client的通过RPC的Proxy与NameNode交互。在client端会有两个代理同时存在,分别代表与Active和Standby的NameNode的连接。由于Client端有Retry机制,当与Active NameNode正常通信的client proxy收到RPC返回的StandbyException时,说明这个Active NameNode已经变成了Standby模式,所以触发dfs.client.failover.proxy.provider.[nameservice ID]这个参数指定的类来做failover,目前唯一的实现是ConfiguredFailoverProxyProvider,实现方法就是下次开始把RPC发向另外一个NameNode。此后的RPC都是发往另外一个NameNode,也就是NameNode发生了主从切换。
public synchronized void performFailover(T currentProxy) {
currentProxyIndex = (currentProxyIndex + 1) % proxies.size();
}
(4) Standby processing editlogs form Active