
HStore存储是HBase存储的核心了,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。
1,HBase的架构:
LSM - 解决磁盘随机写问题(顺序写才是王道);
HFile - 解决数据索引问题(只有索引才能高效读);
WAL - 解决数据持久化(面对故障的持久化解决方案);
zooKeeper - 解决核心数据的一致性和集群恢复;
Replication - 引入类似MySQL的数据复制方案,解决可用性;
此外还有:自动分拆Split、自动压缩(compaction,LSM的伴生技术)、自动负载均衡、自动region迁移。
HBase集群需要依赖于一个Zookeeper ensemble。HBase集群中的所有节点以及要访问HBase
的客户端都需要能够访问到该Zookeeper ensemble。HBase自带了Zookeeper,但为了方便
其他应用程序使用Zookeeper,最好使用单独安装的Zookeeper ensemble。此外,Zookeeper ensemble一般配置为奇数个节点,并且Hadoop集群、Zookeeper ensemble、HBase集群是三个互相独立的集群,并不需要部署在相同的物理节点上,他们之间是通过网络通信的。
Hbase和hadoop的关系可以如下图所示:

HBase 结点之间时间不一致造成regionserver启动失败
2,Hadoop和Hbase的版本匹配
下面在给列出官网信息:
下面面符号的含义:
S =支持并且测试,
X = 不支持,
NT =应该可以,但是没有测试。如下图所示:
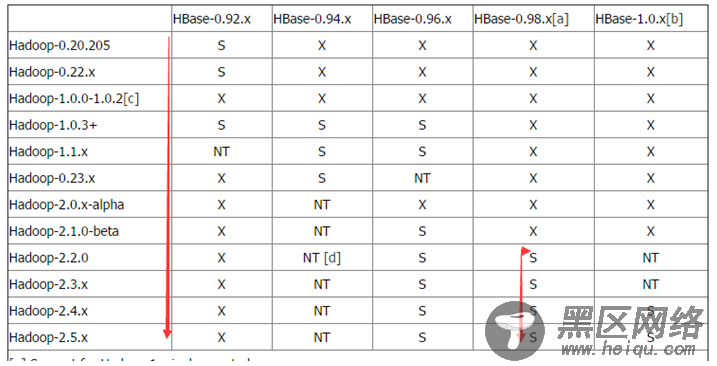
3,下载地址
从Step2的图中看出,由于我安装的hadoop是2.3.0,所以可以选择0.96以上的hbase版本,这里选择比较稳健的0.98版本的hbase下载。
进hbase官网
进去,找到下载,进去
再进去,选择HTTP,第一个mirrors,找到下载地址如下:
4 ,开始安装
tar zxvf hbase-0.98.9-hadoop2-bin.tar.gz -C /home/hadoop/src/
5,配置
5.1),配置hbase-site.xml
开始修改配置文件:/home/hadoop/src/hbase-0.98.9-hadoop2/conf
完全分布式安装:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://192.168.52.128:9000/hbase</value>
<description>HBase数据存储目录</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>指定HBase运行的模式:false:单机/伪分布;true:完全分布</description>
</property>
<property>
<name>hbase.master</name>
<value>hdfs://192.168.52.128:60000</value>
<description>指定Master位置</description>
</property>