
# 在 cdh1 节点上运行 $ sudo service spark-master start # 在 cdh1 节点上运行,如果 hadoop 集群配置了 kerberos,则运行之前需要先获取 spark 用户的凭证 # kinit -k -t /etc/spark/conf/spark.keytab spark/cdh1@JavaCHEN.COM $ sudo service spark-history-server start # 在cdh2、cdh3 节点上运行 $ sudo service spark-worker start
停止脚本:
$ sudo service spark-master stop $ sudo service spark-worker stop $ sudo service spark-history-server stop
当然,你还可以设置开机启动:
$ sudo chkconfig spark-master on $ sudo chkconfig spark-worker on $ sudo chkconfig spark-history-server on
3.2 使用 Spark 自带脚本管理集群另外,你也可以使用 Spark 自带的脚本来启动和停止,这些脚本在 /usr/lib/spark/sbin 目录下:
$ ls /usr/lib/spark/sbin slaves.sh spark-daemons.sh start-master.sh stop-all.sh spark-config.sh spark-executor start-slave.sh stop-master.sh spark-daemon.sh start-all.sh start-slaves.sh stop-slaves.sh
在master节点修改 /etc/spark/conf/slaves 文件添加worker节点的主机名称,并且还需要在master和worker节点之间配置无密码登陆。
# A Spark Worker will be started on each of the machines listed below. cdh2 cdh3
然后,你也可以通过下面脚本启动 master 和 worker:
$ cd /usr/lib/spark/sbin $ ./start-master.sh $ ./start-slaves.sh
当���,你也可以通过spark-class脚本来启动,例如,下面脚本以standalone模式启动worker:
$ ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://cdh1:18080
3.3 访问web界面你可以通过 :18080/ 访问 spark master 的 web 界面。
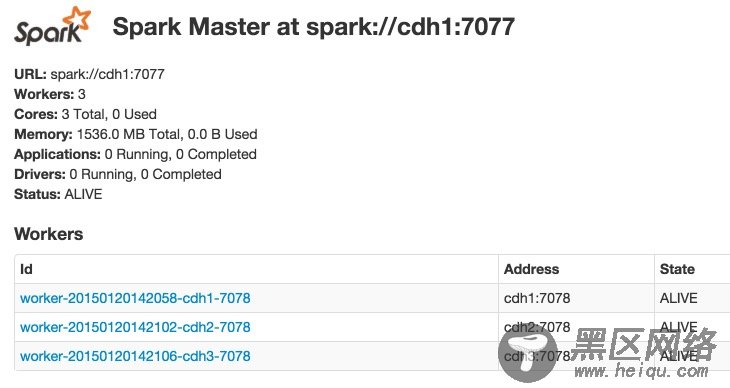
访问Spark History Server页面::18082/。
注意:我这里使用的是CDH版本的 Spark,Spark master UI的端口为18080,不是 Apache Spark 的 8080 端口。CDH发行版中Spark使用的端口列表如下:
7077 – Default Master RPC port
7078 – Default Worker RPC port
18080 – Default Master web UI port
18081 – Default Worker web UI port
18080 – Default HistoryServer web UI port
4. 测试Spark可以以本地模式运行,也支持三种集群管理模式:
另外 Spark 的 EC2 launch scripts 可以帮助你容易地在Amazon EC2上启动standalone cluster.
在集群不是特别大,并且没有 mapReduce 和 Spark 同时运行的需求的情况下,用 Standalone 模式效率最高。
Spark可以在应用间(通过集群管理器)和应用中(如果一个 SparkContext 中有多项计算任务)进行资源调度。
4.1 Standalone 模式该模式中,资源调度是Spark框架自己实现的,其节点类型分为Master和Worker节点,其中Driver节点运行在Master节点中,并且有常驻内存的Master进程守护,Worker节点上常驻Worker守护进程,负责与Master通信。
Standalone 模式是Master-Slaves架构的集群模式,Master存在着单点故障问题,目前,Spark提供了两种解决办法:基于文件系统的故障恢复模式,基于Zookeeper的HA方式。
Standalone 模式需要在每一个节点部署Spark应用,并按照实际情况配置故障恢复模式。
你可以使用交互式命令spark-shell、pyspark或者spark-submit script连接到集群,下面以wordcount程序为例:
$ spark-shell --master spark://cdh1:7077 scala> val file = sc.textFile("hdfs://cdh1:8020/tmp/test.txt") scala> val counts = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _) scala> counts.count() scala> counts.saveAsTextFile("hdfs://cdh1:8020/tmp/output")
如果运行成功,可以打开浏览器访问 :4040 查看应用运行情况。
运行过程中,可能会出现下面的异常: