动态内存分配器维护一个大块区域,也就是堆,处理动态的内存分配请求。分配器将堆视为一组不同大小的块的集合来维护,每个块要么是已分配的,要么是空闲的。
实现动态内存分配要考虑以下问题:
(1)空闲块组织:我们如何记录空闲块?
(2)放置:我们如何选择一个合适的空闲块来放置一个新分配的块?
(3)分割:在我们将一个新分配的块放置到某个空闲块之后,我们如何处理这个空闲块中的剩余部分?
(4)合并:我们如何处理一个刚刚被释放的块?
任何分配器都需要一些开销,需要数据结构来记录信息,区分块边界,区分已分配块和空闲块等。大多数实现方式都把信息放在块本身内部。隐式空闲链表就是通过每个块的头部中存放的信息可以方便的定位到下一个块的位置。头部一般就是本块的大小及使用情况(分配或空闲)。
本块的起始地址加上本块的大小就是下一个块的起始地址。
本文使用的控制块结构如下:
struct mem_block
{
int size; // 本块的大小,包括控制结构
int is_free; // 使用情况,1为空闲,0为已分配
}
为了内存对齐,这里is_free也是用4字节的int存储。起始控制信息根本不需要这么多,此处为了方便理解。
下面是一个块的表示图
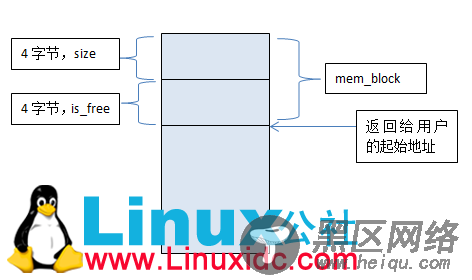
返回给用户的区域并不包含控制信息。
当接收到一个内存分配请求时,从头开始遍历堆,找到一个空闲的满足大小要求的块,若有剩余,将剩余部分变成一个新的空闲块,更新相关块的控制信息。调整起始位置,返回给用户。
释放内存时,仅需把使用情况标记为空闲即可。
隐式空闲链表的优点是简单。显著的缺点是任何操作的开销,例如放置分配的块,要求空闲链表的搜索与堆中已分配块和空闲块的总数呈线性关系。
搜索可以满足请求的空闲块时,常见的策略有以下几种:
(1)首次适应法(First Fit):选择第一个满足要求的空闲块
(2)最佳适应法(Best Fit):选择满足要求的,且大小最小的空闲块
(3)最坏适应法(Worst Fit):选择最大的空闲块
(4)循环首次适应法(Next Fit):从上次分配位置开始找到第一个满足要求的空闲块
这里不对各种策略的优劣进行比较了。