近期闲来无事,想着闲着也是闲着,不如给自己搞点事情做!敢想敢做,于是选择了给微信小程序做个 仿iPhone通讯录 效果的自定义组件。
先来整理一下,瞧瞧需要实现的核心功能。
按照第一个字的首字母排序;
实现输入搜索功能;
侧边栏字母导航;
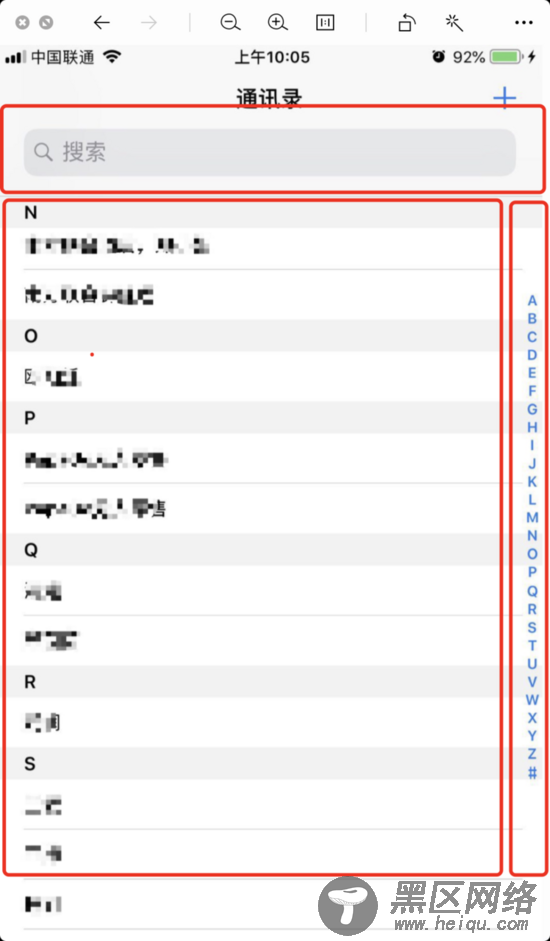
基本上分为3块:
顶部的搜索区域;
内容的展示区域;
侧边字母导航栏区域;
// index.wxml <view> <!-- 顶部搜索区域 --> <view> </view> <!-- 内容区域 --> <scroll-view> </scroll-view> <!-- 侧边导航 --> <view> </view> </view>
【顶部的搜索区域】
一目了然就直接贴代码了。
<view> // 这里或许有人要问,为啥不用小程序的label组件呢。?_? // 原因就是...我就不用,你还能咬我?!^(oo)^ // 哈哈哈哈~开个玩笑,其实是小程序的label组件还没支持input! <view> <icon></icon> <input type="text" placeholder="搜索" /> </view> </view>
【内容的展示区域】
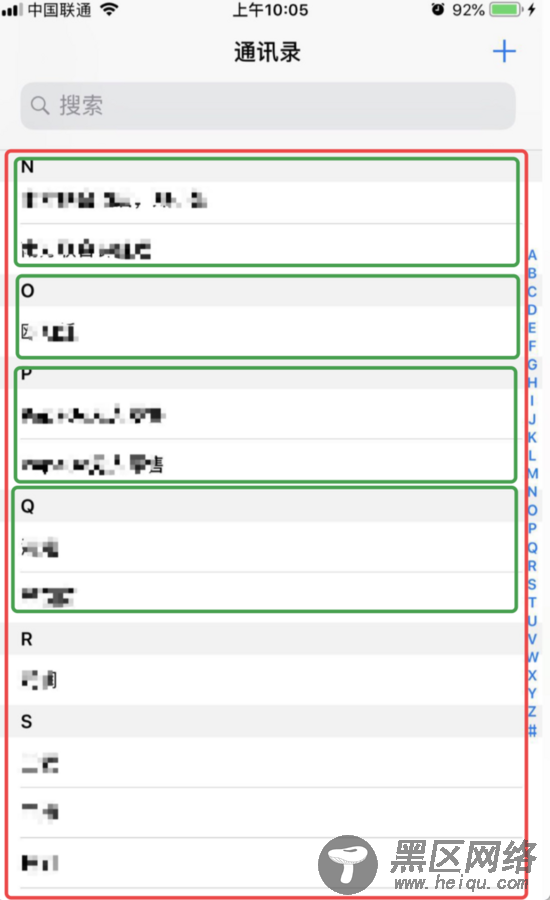
再说一目了然会不会被打呢?:joy:
根据图片就可以看出来,存在2个区域。
红框包围的外框,负责圈定展示的范围;
绿框包围的范围,包含有字母标题和对应的子项。
代码如下:
<scroll-view> <view> <view>这里是字母标题。</view> <view> <span>这里当然是展示的内容啦。</span> </view> </view> </scroll-view>
【侧边字母导航栏区域】
为了节省一下文章的篇幅,这里就不贴图了,很简单,就是并排下来就好了。
<view> <view>这里是输出字母。</view> </view>
接下来是wxss的样式了。
考虑到wxss的样式较多,我就直接贴 代码链接 吧,有兴趣的童鞋可以瞧瞧。
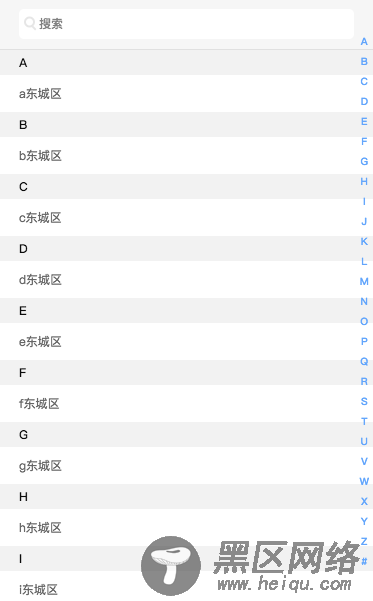
完成之后,是时候贴个效果图了。(不许吐槽丑,宝宝会不开心的!:pensive:)
结构样式弄完了,也贴一下自定组件的基础文件
// index.json { "component": true }
// index.js Component({ properties: {}, // 组件的对外属性 data: {}, // 组件的内部数据 lifetimes: {}, // 生命周期 methods: {} // 事件 });
现在开始实现功能了!!!
按照第一个字的首字母排序
说实话,实现这块功能呢,我是没啥头绪的,所以这个时候就要求助伟大的“度娘/Google”了。
经过楼主“遍寻网络”,查找到如下页面的源码参考:

因楼主问题,遗忘了该网址,如有知道的童鞋,贴个链接告诉下楼主,楼主立马麻溜的加上。 源码的原理大概描述下:
收录 20902 个汉字和 375 个多音字的 Unicode 编码,然后用JS切割首字母并转换成 Unicode 进行对比,最后返回对应首字母的拼音。
// 汉字对应的Unicode编码文件 // oMultiDiff = 多音字 | firstLetterMap = 汉字 import firstStore from './firstChineseLetter'; // 获取首字母拼音 function getFirstLetter (val) { const firstVal = val.charAt(0); if (/.*[\u4e00-\u9fa5]+.*/.test(firstVal)) { // 处理中文字符 // 转换成Unicode编码,与firstStore里面的数据进行对比,然后返回对应的参数 const code = firstVal.charCodeAt(0); // 转换成Unicode编码 return code in firstStore.oMultiDiff ? firstStore.oMultiDiff[code] : firstStore.firstLetterMap.charAt(code - 19968); } else { // 这里处理非中文 // 检测是否字母,如果是就直接返回大写的字母 // 不是的话,返回“#” return /^[a-zA-Z]+$/.test(firstVal) ? firstVal.toUpperCase() : '#'; } } getFirstLetter('东城区'); // 输出结果:D
获取首字母的方法有了之后,就该对数据进行处理了。
首先定义一下组件所需要的参数。