
create index idx_deptid on students(dept_id);
explain select count(*) from students a inner join dept b on a.dept_>explain select count(*) from students_noindex a inner join dept b on a.dept_>select SQL_NO_CACHE count(*) from students a inner join dept b on a.dept_>select SQL_NO_CACHE count(*) from students_noindex a inner join dept b on a.dept_>
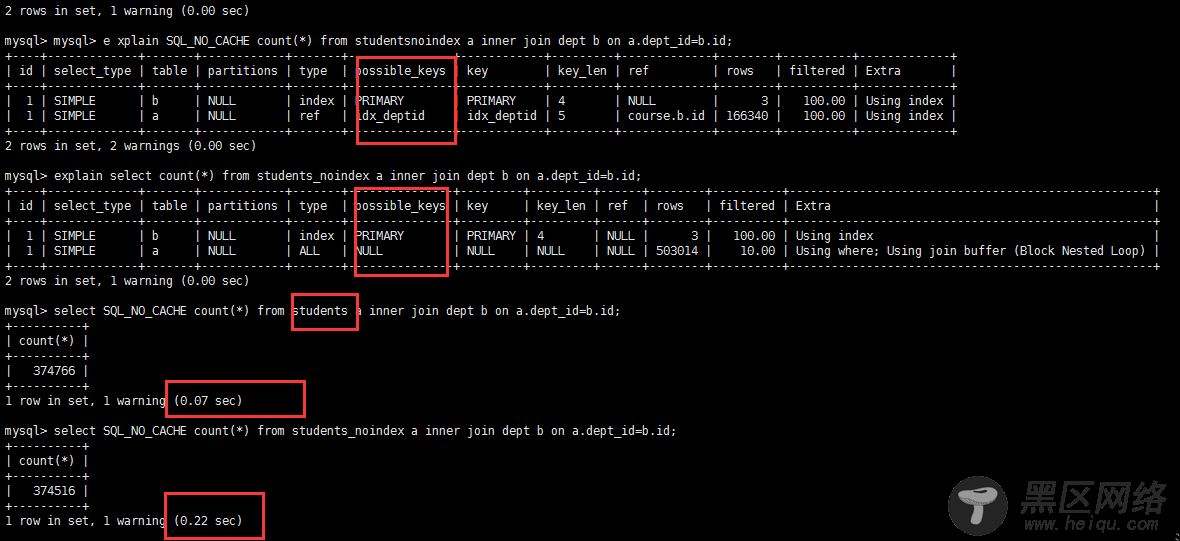
在关联字段上加了索引 查询时间只用了0.07s 用时 比没有走索引的快了很多很多
总结:
优化手段不只一种 ,要根据实际情况,很多情况都是以最低成本去处理, 例如
有可能加索引就能解决, 有可能解决不了,语句的写法的可能有问题(例如语句有函数,表达式),也有可能去改表的结构(例如增加冗余字段),有可能数据库瓶颈问题, 网络情况问题,服务器性能IO 问题,等等。
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx