
RAID,一般翻译为磁盘阵列,全称是 Redundant Arrays of Inexpensive Disk,最初的构想是源于加州大学伯克利分校的一个研究小组的项目,他们希望通过大量廉价的硬盘来组建价格便宜,可用性高的磁盘阵列。但是RAID发展到今天,已经背离了当初价格便宜的初衷。但是RAID也带来了另外的好处,如何合理选择RAID的级别,可以构建出具有更高可用性,更好地容错的磁盘。
RAID主要分为软件RAID和硬件RAID,软件RAID主要是通过操作系统来实现,这样会增加CPU的负担,所以在实际场景中极少使用。硬件RAID使用独立的硬件设备和控制芯片,整体性能优于软件RAID。RAID有不同的规范,但是总体上可以分为两种:标准RAID和混合RAID。虽然现在的RAID有很多不同的规范,但是很多规范只是一种过渡性的实验产品,在实际的生产环境中几乎不使用。
1、标准RAID
1.1 RAID 0
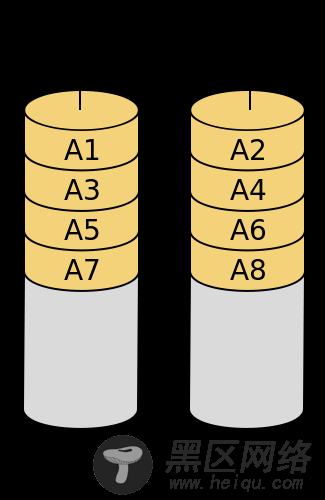
RAID 0也称为条带(strping),它将两个以上的硬盘串联起来,成为一个大容量的磁盘。在存储数据时,数据分散存储在这些磁盘中。因为数据读写都可以并行的进行,所以在所有的级别中,RIID的速度是最快的。但是RAID既没有冗余功能,也不提供容错能力。如果有一个物理磁盘损坏,所有的数据都会丢失。所以,RAID只是在一些对数据安全性要求不高,但是速度要求较高的场景下使用,比如视频,图像等工作站。
1.2 RAID 1
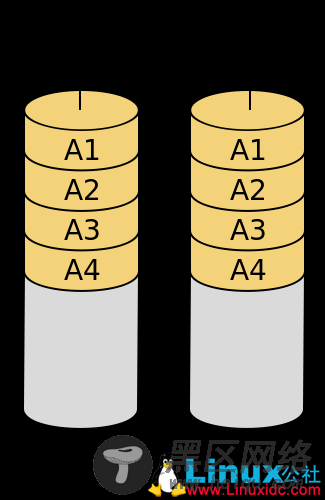
RAID 1称为镜像技术,需要两块以上的硬盘互作镜像。也就是说,主盘上的数据和镜像盘上的数据完全一样。因此,在多线程的操作系统会大大提高数据的读取速度。RAID 1 的可靠性非常高,只要有一块硬盘正常就可以保证数据的完整性。但是RAID的缺点是浪费了大量的存储空间。
RAID2-RAID4属于实验性的产品实际生产环境很少使用。
1.3 RAID 5
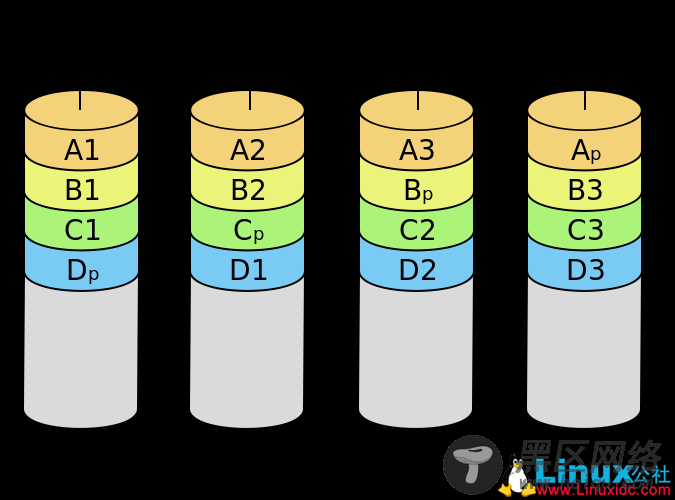
RAID 5引入了数据校验的功能,并且校验的数据是分散的存储在各块硬盘上。RAID 5 实际上是速度与可靠性的一种折衷方案,在实际场景中应用较多。与RAID相比,存储成本比较便宜。RAID 5至少需要3块磁盘来实现。
1.4 RAID 6
与RAID 5相比,RAID增加了第二个独立的信息校验块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。RAID 6至少需要4块以上的磁盘。

2、 混合RAID
2.1 JBOD
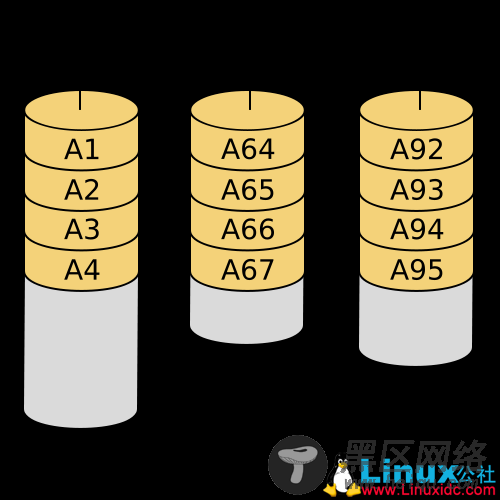
严格来讲JBOD(Just a Bunch Of Disks)并不属于RAID的等级,JBOD并没有严格的规范,主要是用于实现将各个独立的硬盘空间在逻辑上组合成一个大的硬盘。如果硬盘损毁,则存在上面的数据将无法救回。若第一块硬盘损坏,将丢失所有的数据,危险程度与RAID 0相比有过之无不及。但是JBOD也有它的应用场景,例如Hadoop就鼓励使用JBOD,因为Hadoop由自己的一套容灾方案。
2.2 RAID 01
RAID 01是RAID 0与RAID 1的一种组合。主要实现方案是先将数据分成两组,然后再对数据进行镜像映射。即先实现RAID 0,再实现RAID 1。
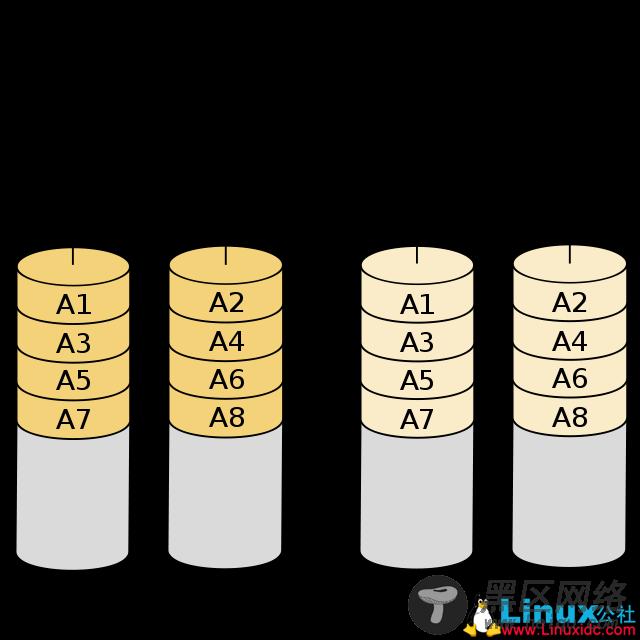
2.3 RAID 10
RAID 10与RAID 01恰好相反,是先进行数据镜像,然后才对数据进行分组。

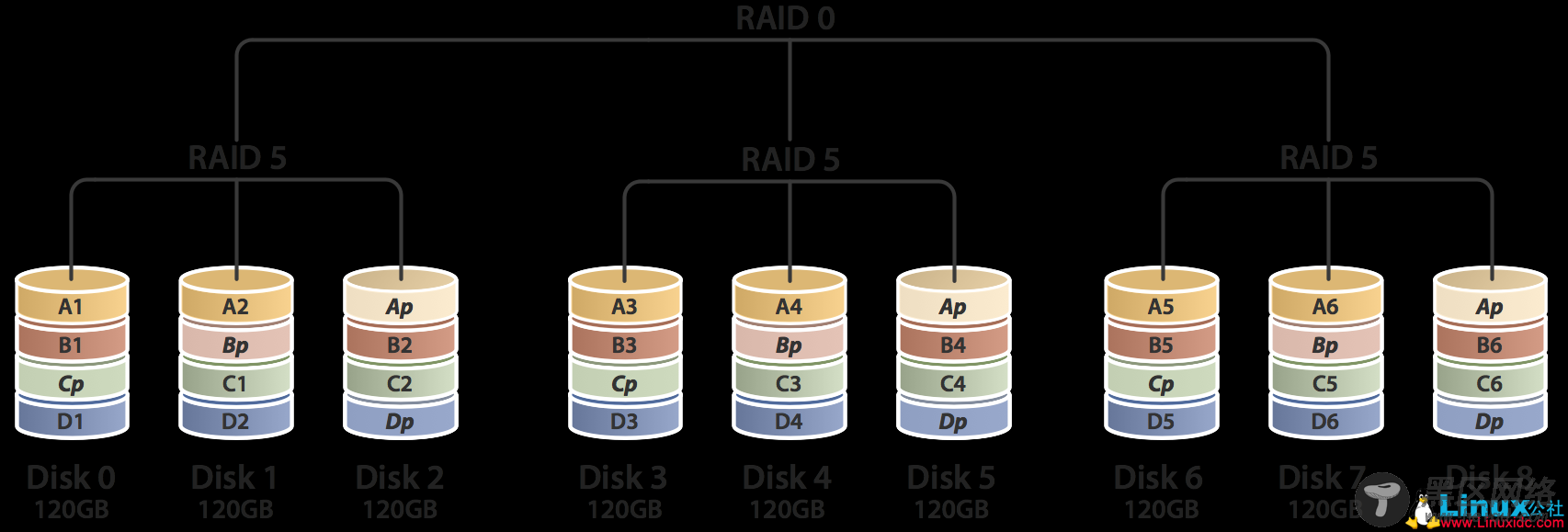
2.4 RAID 50
RAID 5与RAID 0的结合,先作RAID 5,在作RAID 0,也就是对多组RAID 5构成条带化的访问。RAID 50以RAID 5为基础,而RAID 5至少需要3块硬盘,要以多组RAID 5构成RAID 50,因此RAID至少需要6块硬盘。RAID 50在底层任意一组或多组RAID 5中出现一块硬盘损坏时,仍然可以维持运作,不过任意一组同时出现两块硬盘损坏时,整组RAID 50就会失效。
通过Linux 实现软RAID:
在Linux实现RAID主要是通过mdadm来实现。
mdadm属于模式化的命令,主要模式有:
创建模式
管理模式
监控模式
增长模式
装配模式
mdadm的基本格式为:
#mdadm [mode] [options]
装配模式RAID的选项有:
-l:指定RAID的级别;
-n:指定设备数,即磁盘的个数;
-a:自动为其创建设备文件;
-c,--chunk 指定分割数据块的大小
1. 实现RAID 0:
准备工作:
两个1G大小的磁盘分区。