
Map类集合中的存储单位是Key-Value键值对,Map类使用一定的哈希算法形成比较均匀的哈希值作为Key,Value值挂在Key上。
一、Map类特点:
1、Key不能重复,Value可重复
2、Value可以是List、Map、Set类对象
3、KV是否允许为null,以实现类约束为准
二、Map除提供增删改查外,还有三个Map特有方法。
1、返回所有的Key
Set<K> keySet();
返回Map类杜希昂中的Key的Set视图。
2、返回所有value
Collection<V> values();
返回Map类对象中的所有Value的Collection视图。
3、返回所有K-V键值对
Set<Map.Entry<K, V>> entrySet();
返回Map类对象中的K-V键值对的Set视图。
这些函数返回的视图支持清除操作(remove、clear),不支持修改和添加元素。
三、主要的Map类集合(图来自Java开发手册pdf)
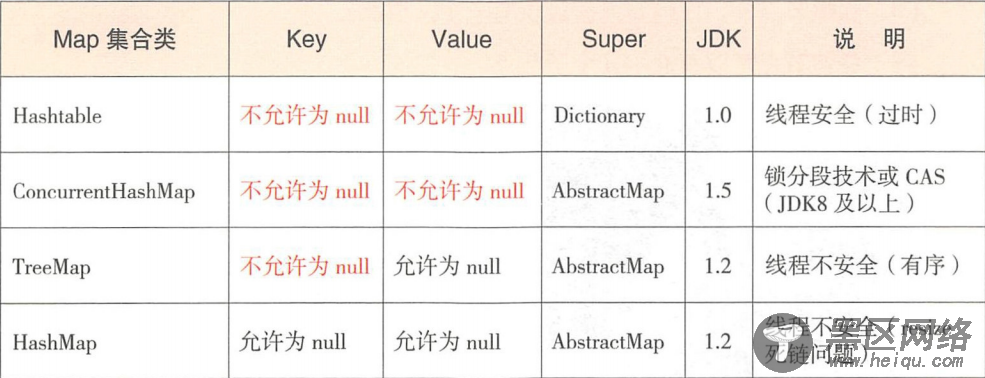
Hashtable逐渐弃用,ConcurrentHashMap多线程比HashMap安全,但本文主要分析HashMap。
-------------------------------------------------------------------------------------------
HashMap
一、哈希类集合的三个基本存储概念
名称 说明table 存储所有节点数据的数组
slot 哈希槽。即table[i]这个位置
bucket 哈希桶。table[i]上所有元素形成的表或数的集合
图示:

链表Node“Node是HashMap的一个静态内部类。
>//>Node是单向链表,实现了Map.Entry接口 >static >class Node<K,V> >implements Map.Entry<K,V> { >final >int hash; >final K key; V value; Node<K,V> next; >//>构造函数 Node(>int hash, K key, V value, Node<K,V> next) { >this.hash = hash; >this.key = key; >this.value = value; >this.next = next; } >//> getter and setter ... toString ... >public >final K getKey() { >return key; } >public >final V getValue() { >return value; } >public >final String toString() { >return key + "=" + value; } >public >final >int hashCode() { >return Objects.hashCode(key) ^ Objects.hashCode(value); } >public >final V setValue(V newValue) { V oldValue = value; value = newValue; >return oldValue; } >public >final >boolean equals(Object o) { >if (o == >this) >return >true; >if (o >instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; >if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) >return >true; } >return >false; } }
红黑树TreeNode:通过特定着色的旋转(左旋、右旋)来保证从根节点到叶子节点的最长路径不超过最短路径的2倍的二叉树,相比AVL树,更加高效的完成插入和删除操作后的自平衡调整。最坏运行时间为O(logN).
>static >final >class TreeNode<K,V> >extends LinkedHashMap.Entry<K,V> { TreeNode<K,V> parent; >//> red-black tree links TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; >//> needed to unlink next upon deletion >boolean red; TreeNode(>int hash, K key, V val, Node<K,V> next) { >super(hash, key, val, next); } >/**> * Returns root of tree containing this node. >*/ >final TreeNode<K,V> root() { >for (TreeNode<K,V> r = >this, p;;) { >if ((p = r.parent) == >null) >return r; r = p; } }
二、HashMap定义变量
>/**> * 默认初始容量16(必须是2的幂次方) >*/ >static >final >int DEFAULT_INITIAL_CAPACITY = 1 << 4; >/**> * 最大容量,2的30次方 >*/ >static >final >int MAXIMUM_CAPACITY = 1 << 30; >/**> * 默认加载因子,用来计算threshold >*/ >static >final >float DEFAULT_LOAD_FACTOR = 0.75f; >/**> * 链表转成树的阈值,当桶中链表长度大于8时转成树 threshold = capacity * loadFactor >*/ >static >final >int TREEIFY_THRESHOLD = 8; >/**> * 进行resize操作时,若桶中数量少于6则从树转成链表 >*/ >static >final >int UNTREEIFY_THRESHOLD = 6; >/**> * 桶中结构转化为红黑树对应的table的最小大小 当需要将解决 hash 冲突的链表转变为红黑树时, 需要判断下此时数组容量, 若是由于数组容量太小(小于 MIN_TREEIFY_CAPACITY ) 导致的 hash 冲突太多,则不进行链表转变为红黑树操作, 转为利用 resize() 函数对 hashMap 扩容 >*/ >static >final >int MIN_TREEIFY_CAPACITY = 64; >/**> 保存Node<K,V>节点的数组 该表在首次使用时初始化,并根据需要调整大小。 分配时, 长度始终是2的幂。 >*/ >transient Node<K,V>[] table; >/**> * 存放具体元素的集 >*/ >transient Set<Map.Entry<K,V>> entrySet; >/**> * 记录 hashMap 当前存储的元素的数量 >*/ >transient >int size; >/**> * 每次更改map结构的计数器 >*/ >transient >int modCount; >/**> * 临界值 当实际大小(容量*负载因子)超过临界值时,会进行扩容 >*/ >int threshold; >/**> * 负载因子 >*/ >final >float loadFactor;
默认容量:16 DEFAULT_INITIAL_CAPACITY = >1 << >4
自定义初始化容量:构造函数 ↓
Map容量一定为2的幂次。
默认加载因子:0.75 DEFAULT_LOAD_FACTOR = >0.75f
>自定义负载因子:构造函数 ↓
>桶中节点从链表转化为红黑树:节点数大于8
>桶中元素从红黑树返回为链表:节点数小于等于6
>threshold:临界值 = 容量×负载因子,当实际容量大于临界值,为了减小哈希冲突,进行扩容。
三、构造函数