
在AWS执行批处理任务时,允许按需配置多部分作业处理的应用架构,可用于对异构的系统的瞬时或延迟部署,并可扩展为“网格”型工作节点,通过并联的大批量任务处理实现快速收敛。面向批处理应用程序现在可以有很多的地方利用这种风格按需加工,包括理赔处理,大规模改造,媒体转码和多部分的数据处理工作。
批处理架构通常是高可变使用模式的代名词,即在一段低使用率后有明显的使用峰值(例如,月末的处理)。构建一个批处理架构有很多的方法。本文给出了一个基本的批处理架构,用来支持作业调度,作业状态检查,上传原始数据,输出作业结果,网格管理,以及报告作业性能的数据。
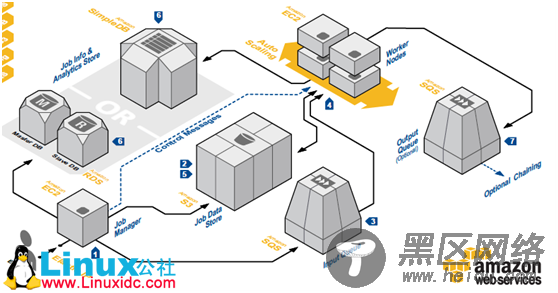
1. 作业管理器部署在EC2 实例上,用户通过Elastic IP与之交互。作业管理器组件控制着进程的接收,调度,启动,管理以及完成批处理作业, 同时也可以访问最终的结果,作业和worker状态,以及作业的进展信息。
2. 原始的作业数据被上传到一个高可用的永久存储器中,即S3.
3. 根据用户的行为,作业管理器将单独的作业任务插入到SQS中。
4. Worker节点是使用AutoScaling组服务的 EC2 实例。 这个组是一个保证了worker 节点健康和可扩展的容器。Worker 节点自动地从输入队列中提取作业部分,同时执行批处理步骤列表中的单独任务。
5. worker 节点产生的中间数据存储在 Amazon S3中。
6. 作业进展信息和统计信息存储在分析存储区。分析存储区既可以用AmazonSimpleDB 或 RDS 实例.
7. 作为可选项, 已完成的任务可以插入到AmazonSQS 队列中,用于链式结构的再次处理节点。