为什么做这个东西,是突然间听一后端同事说起Annie这个东西,发现这个东西下载视频挺方便的,会自动爬取网页中的视频,然后整理成列表。发现用命令执行之后是下面的样子:
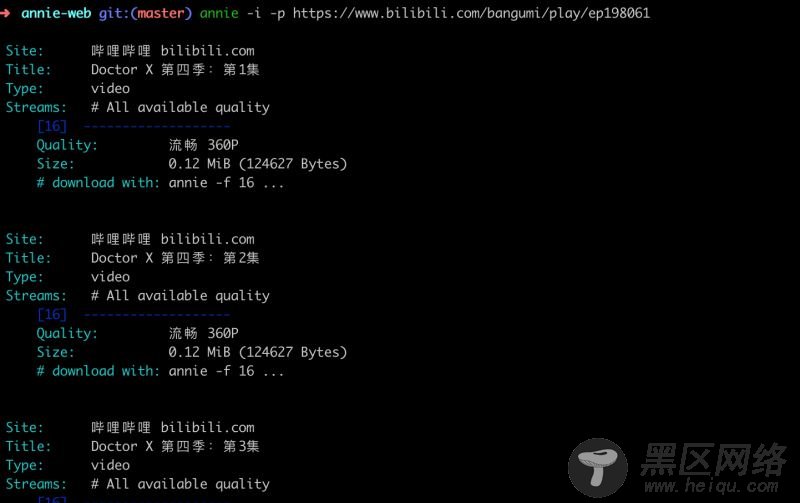
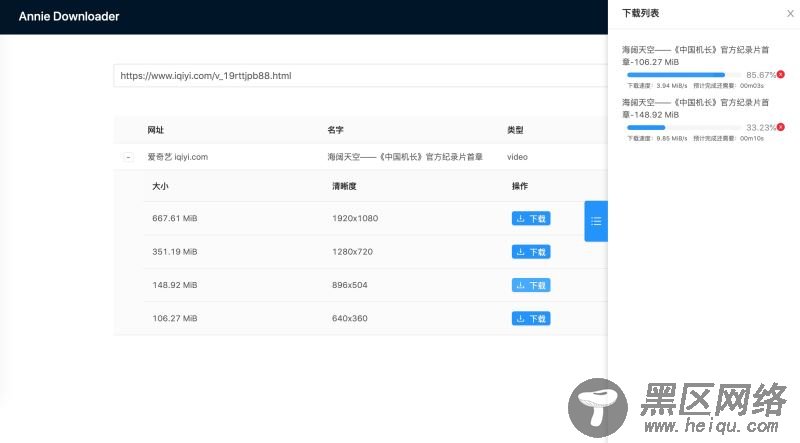
心里琢磨了下,整一个界面玩一下吧。然后就做成下面这个样子了。
列表
下载列表
本文地址仓库:https://github.com/Rynxiao/yh-tools,如果喜欢,欢迎star.
涉及技术
Express 后端服务
Webpack 模块化编译工具
Nginx 主要做文件gzip压缩(发现Express添加gzip有点问题,才弃坑nginx)
Ant-design 前端UI库
React + React Router
WebSocket 进度回传服务
其中还有点小插曲,最开始是使用docker起了一个nginx服务,但是发现内部转发一直有问题,同时获取宿主主机IP也出现了点问题,然后折磨了好久放弃了。(docker研究不深,敬请谅解^_^)
下载部分细节
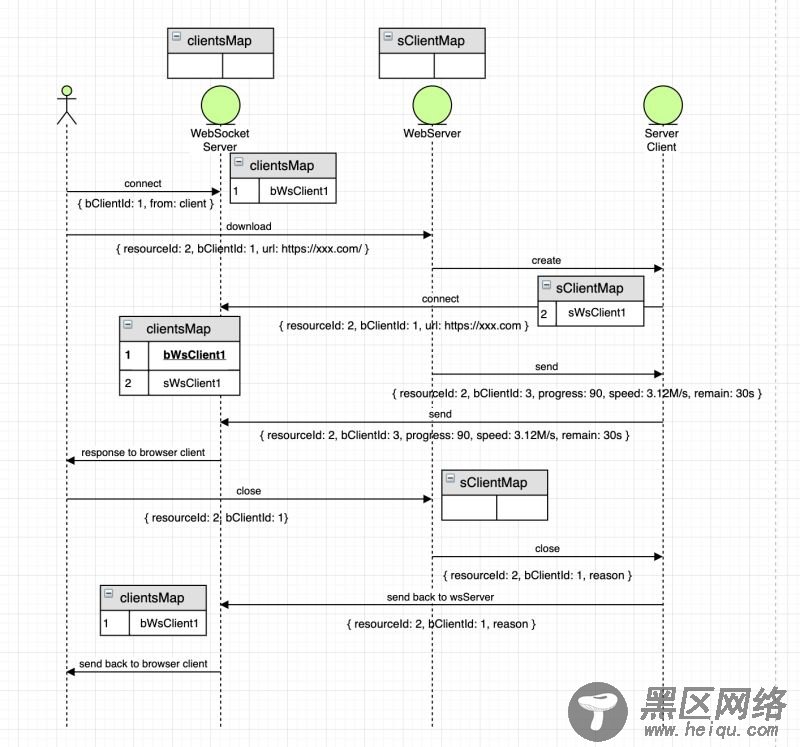
首先浏览器会连接WebSocket服务器,同时在WebSocket服务器上存在一个所有客户端的Map,浏览器端生成一个uuid作为浏览器客户端id,然后将这个链接作为值存进Map中。
客户端:
// list.jsx await WebSocketClient.connect((event) => { const data = JSON.parse(event.data); if (data.event === 'close') { this.updateCloseStatusOfProgressBar(list, data); } else { this.generateProgressBarList(list, data); } }); // src/utils/websocket.client.js async connect(onmessage, onerror) { const socket = this.getSocket(); return new Promise((resolve) => { // ... }); } getSocket() { if (!this.socket) { this.socket = new WebSocket( `ws://localhost:${CONFIG.PORT}?from=client&id=${clientId}`, 'echo-protocol', ); } return this.socket; }
服务端:
// public/javascript/websocket/websocket.server.js connectToServer(httpServer) { initWsServer(httpServer); wsServer.on('request', (request) => { // uri: ws://localhost:8888?from=client&id=xxxx-xxxx-xxxx-xxxx logger.info('[ws server] request'); const connection = request.accept('echo-protocol', request.origin); const queryStrings = querystring.parse(request.resource.replace(/(^\/|\?)/g, '')); // 每有连接连到websocket服务器,就将当前连接保存到map中 setConnectionToMap(connection, queryStrings); connection.on('message', onMessage); connection.on('close', (reasonCode, description) => { logger.info(`[ws server] connection closed ${reasonCode} ${description}`); }); }); wsServer.on('close', (connection, reason, description) => { logger.info('[ws server] some connection disconnect.'); logger.info(reason, description); }); }
然后在浏览器端点击下载的时候,会传递两个主要的字段resourceId(在代码中由parentId和childId组成)和客户端生成的bClientId。这两个id有什么用呢?
每次点击下载,都会在Web服务器中生成一个WebSocket的客户端,那么这个resouceId就是作为在服务器中生成的WebSocket服务器的key值。
bClientId主要是为了区分浏览器的客户端,因为考虑到同时可能会有多个浏览器接入,这样在WebSocket服务器中产生消息的时候,就可以用这个id来区分应该发送给哪个浏览器客户端
客户端:
// list.jsx http.get( 'download', { code, filename, parent_id: row.id, child_id: childId, download_url: url, client_id: clientId, }, ); // routes/api.js router.get('/download', async (req, res) => { const { code, filename } = req.query; const url = req.query.download_url; const clientId = req.query.client_id; const parentId = req.query.parent_id; const childId = req.query.child_id; const connectionId = `${parentId}-${childId}`; const params = { code, url, filename, parent_id: parentId, child_id: childId, client_id: clientId, }; const flag = await AnnieDownloader.download(connectionId, params); if (flag) { await res.json({ code: 200 }); } else { await res.json({ code: 500, msg: 'download error' }); } }); // public/javascript/annie.js async download(connectionId, params) { //... // 当annie下载时,会进行数据监听,这里会用到节流,防止进度回传太快,websocket服务器无法反应 downloadProcess.stdout.on('data', throttle((chunk) => { try { if (!chunk) { isDownloading = false; } // 这里主要做的是解析数据,然后发送进度和速度等信息给websocket服务器 getDownloadInfo(chunk, ws, params); } catch (e) { downloadSuccess = false; WsClient.close(params.client_id, connectionId, 'download error'); this.stop(connectionId); logger.error(`[server annie download] error: ${e}`); } }, 500, 300)); }