Vue.js通过简洁的API提供高效的数据绑定和灵活的组件系统。在前端纷繁复杂的生态中,Vue.js有幸受到一定程度的关注,目前在GitHub上已经有5000+的star。本文将从各方面对Vue.js做一个深入的介绍。
Vue.js 是我在2014年2月开源的一个前端开发库,通过简洁的 API 提供高效的数据绑定和灵活的组件系统。在前端纷繁复杂的生态中,Vue.js有幸受到一定程度的关注,目前在 GitHub上已经有5000+的star。本文将从各方面对Vue.js做一个深入的介绍。
开发初衷
2013年末,我还在Google Creative Lab工作。当时在项目中使用了一段时间的Angular,在感叹数据绑定带来生产力提升的同时,我也感到Angular的API设计过于繁琐,使得学习曲线颇为陡峭。出于对Angular数据绑定原理的好奇,我开始 “造轮子”,自己实现了一个非常粗糙的、基于依赖收集的数据绑定库。这就是Vue.js的前身。同时在实际开发中,我发现用户界面完全可以用嵌套的组件树来描述,而一个组件恰恰可以对应MVVM中的ViewModel。于是我决定将我的数据绑定实验改进成一个真正的开源项目,其核心思想便是 “数据驱动的组件系统”。
MVVM 数据绑定
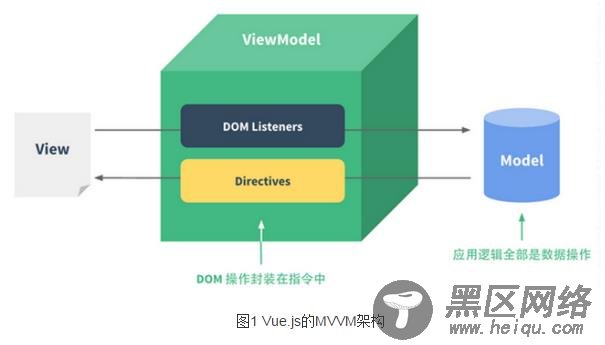
MVVM的本质是通过数据绑定链接View和Model,让数据的变化自动映射为视图的更新。Vue.js在数据绑定的API设计上借鉴了Angular的指令机制:用户可以通过具有特殊前缀的HTML 属性来实现数据绑定,也可以使用常见的花括号模板插值,或是在表单元素上使用双向绑定:
<!-- 指令 --> <span v-text="msg"></span> <!-- 插值 --> <span>{{msg}}</span> <!-- 双向绑定 --> <input v-model="msg">
插值本质上也是指令,只是为了方便模板的书写。在模板的编译过程中,Vue.js会为每一处需要动态更新的DOM节点创建一个指令对象。每当一个指令对象观测的数据变化时,它便会对所绑定的目标节点执行相应的DOM操作。基于指令的数据绑定使得具体的DOM操作都被合理地封装在指令定义中,业务代码只需要涉及模板和对数据状态的操作即可,这使得应用的开发效率和可维护性都大大提升。
与Angular不同的是,Vue.js的API里并没有繁杂的module、controller、scope、factory、service等概念,一切都是以“ViewModel 实例”为基本单位:
<!-- 模板 --> <div> {{msg}} </div> // 原生对象即数据 var data = { msg: 'hello!' } // 创建一个 ViewModel 实例 var vm = new Vue({ // 选择目标元素 el: '#app', // 提供初始数据 data: data })
渲染结果:
<div> hello! </div>
在渲染的同时,Vue.js也已经完成了数据的动态绑定:此时如果改动data.msg的值,DOM将自动更新。是不是非常简单易懂呢?除此之外,Vue.js对自定义指令、过滤器的API也做了大幅的简化,如果你有Angular的开发经验,上手会非常迅速。
数据观测的实现
Vue.js的数据观测实现原理和Angular有着本质的不同。了解Angular的读者可能知道,Angular的数据观测采用的是脏检查(dirty checking)机制。每一个指令都会有一个对应的用来观测数据的对象,叫做watcher;一个作用域中会有很多个watcher。每当界面需要更新时,Angular会遍历当前作用域里的所有watcher,对它们一一求值,然后和之前保存的旧值进行比较。如果求值的结果变化了,就触发对应的更新,这个过程叫做digest cycle。脏检查有两个问题:
1.任何数据变动都意味着当前作用域的每一个watcher需要被重新求值,因此当watcher的数量庞大时,应用的性能就不可避免地受到影响,并且很难优化。
2.当数据变动时,框架并不能主动侦测到变化的发生,需要手动触发digest cycle才能触发相应的DOM 更新。Angular通过在DOM事件处理函数中自动触发digest cycle部分规避了这个问题,但还是有很多情况需要用户手动进行触发。
Vue.js采用的则是基于依赖收集的观测机制。从原理上来说,和老牌MVVM框架Knockout是一样的。依赖收集的基本原理是:
1.将原生的数据改造成 “可观察对象”。一个可观察对象可以被取值,也可以被赋值。
2.在watcher的求值过程中,每一个被取值的可观察对象都会将当前的watcher注册为自己的一个订阅者,并成为当前watcher的一个依赖。
3.当一个被依赖的可观察对象被赋值时,它会通知所有订阅自己的watcher重新求值,并触发相应的更新。
4.依赖收集的优点在于可以精确、主动地追踪数据的变化,不存在上述提到的脏检查的两个问题。但传统的依赖收集实现,比如Knockout,通常需要包裹原生数据来制造可观察对象,在取值和赋值时需要采用函数调用的形式,在进行数据操作时写法繁琐,不够直观;同时,对复杂嵌套结构的对象支持也不理想。