
安装环境:
虚拟机:VMware® Workstation 8.0.1(网络桥接)
OS:CentOS 7
JDK版本:jdk-7u79-linux-x64.tar
Scala版本:scala-2.11.7
Spark版本:spark-1.4.0-bin-Hadoop2.4
用户:Hadoop安装Centos时创建的,属于管理员组
第一步:配置SSH
使用hadoop登录系统,在终端运行:
yum install openssh-server

如果提示:
则是因为yum服务被占用,需要强制解锁:
rm -rf /var/run/yum.pid
终端就会联网下载安装包并自行进行安装。安装完成后输入下面指令验证22端口是否打开:
netstat -nat


确定22端口是打开的,然后检查SSH安装正确否,输入
ssh localhost
输入当前用户名和密码按回车确认,说明安装成功,同时ssh登陆需要密码。

这里重点说明一下:
Ssh配置实际上就是配置无密码访问,使用身份凭据代替密码验证,访问时只需要提供一个身份凭据即可,不需要输入密码。那么意思也就是说,每一个用户都有一个独一无二的凭据,要访问谁,就将这个凭据交给谁(即复制到人家的目录下即可)
接下来,在终端输入命令进入Hadoop账户目录:
cd /home/hadoop
再次输入:
ssh-keygen -t rsa
然后一路回车
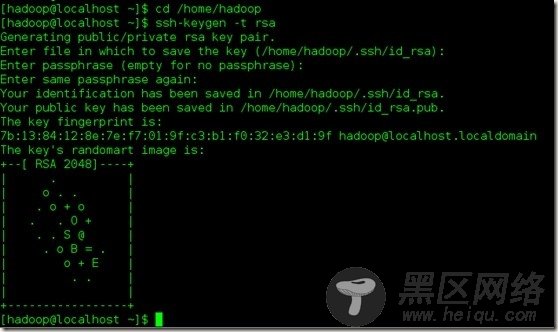
然后我们再次进入.ssh文件夹,然后将id_rsa.pub追加到authorized_keys文件,命令如下:
cd .ssh
顺便查看下本目录下都有什么文件。Id_rsa是属于该账户的私钥,id_rsa.pub是属于该账户的公钥,就是要交出去的。
这里需要多说一句,如果一个主服务器有多个账户要配置无密码访问怎么办?
主服务器下面应该有一个叫authorized_keys 的文件,谁需要配置无密码访问,就把你的公钥追加在这个文件里即可。
cp id_rsa.pub authorized_keys
再次测试无密码登录
ssh localhost

最好是多打开几次终端,测试ssh登录,也可以重启服务测试:
service sshd restart 重启服务
service sshd start 启动服务
service sshd stop 停止服务
netstat -antp | grep sshd 查看是否启动22端口

任何时候遇到权限拒绝在命令前加上sudo 即可,如下就被拒绝了:
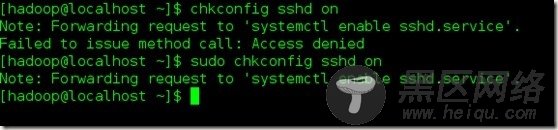
chkconfig sshd on设置开机启动
chkconfig sshd off 禁止SSH开机启动
--------------------------------------分割线 --------------------------------------
CentOS 6.2(64位)下安装Spark0.8.0详细记录
Spark简介及其在Ubuntu下的安装使用
--------------------------------------分割线 --------------------------------------