
由于redis的强大性能很大程度上是因为所有数据都是存储在内存中,然而当出现服务器宕机、redis重启等特殊场景,所有存储在内存中的数据将会丢失,这是无法容忍的事情,所以必须将内存数据持久化。例如:将redis作为数据库使用的;将redis作为缓存服务器使用等场景。
持久化存在的方式?
目前持久化存在两种方式:RDB方式和AOF方式。
RDB方式
RDB持久化是把当前进程数据生成快照保存到硬盘的过程, 触发RDB持久化过程分为手动触发和自动触发。一般存在以下情况会对数据进行快照
根据配置规则进行自动快照; 用户执行SAVE, BGSAVE命令; 执行FLUSHALL命令; 执行复制(replication)时。
优缺点:恢复数据较AOF更快;
RDB方式数据没办法做到实时持久化/秒级持久化;存在老版本Redis服务无法兼容新版RDB格式的问题;非实时性。
AOF方式
以独立日志的方式记录每次写命令(写入的内容直接是文本协议格式 ),重启时再重新执行AOF文件中的命令达到恢复数据的目的。
AOF的工作流程操作: 命令写入(append) 、 文件同步(sync) 、 文件重写(rewrite) 、 重启加载(load)
优点:实时性较好
四、redis过期时间
为什么需要设置过期时间?
涉及的业务场景 有数据更新要求(每秒/每天,根据业务的不同,更新频率也不同)
行情数据,则每秒需要更新; 账户资产等数据 ,则满足每天更新即可;
测试案例分析:
1. 内存占用过大问题【问题描述:面对后台一张"表"400w的资金账户数据量(Hadoop HDFS分布式系统存储映射后的其中一张表),中台接口通过impala查询(类似Oracle查询语法)将得到的结果以bitmap的形式存放至Redis,供其它中台接口调用,最终将数据在前端展示。】
经过计算1byte=8bit, 每个客户进行一次查询存储的key占用的内存400w/8/1024/1024=0.47M,粗略估计2000客户进行查询,存储key占用的内存=2000*0.47(将近1G),如果查询频繁,则必然会出现内存溢出的风险。
优化方法:针对客户的操作频率,一般不会不停地进行数据查询操作,所以可以将客户查询存储的key设置过期时间,这样可以减小内存压力。
五、Redis 架构模式
1.单机版
优点:简单;缺点:内存容量有限;处理能力有限;无法高可用
2.集群版
优点:
主从复制:Redis 的复制(replication)功能允许用户根据一个 Redis 服务器来创建任意多个该服务器的复制品,其中被复制的服务器为主服务器(master),而通过复制创建出来的服务器复制品则为从服务器(slave)。 只要主从服务器之间的网络连接正常,主从服务器两者会具有相同的数据,主服务器就会一直将发生在自己身上的数据更新同步 给从服务器,从而一直保证主从服务器的数据相同。
高可用
无中心架构(不存在哪个节点影响性能瓶颈),少了 proxy 层。
数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布。
可扩展性,可线性扩展到 1000 个节点,节点可动态添加或删除。
高可用性,部分节点不可用时,集群仍可用。通过增加 Slave 做备份数据副本
实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave到 Master的角色提升。
思维导图:
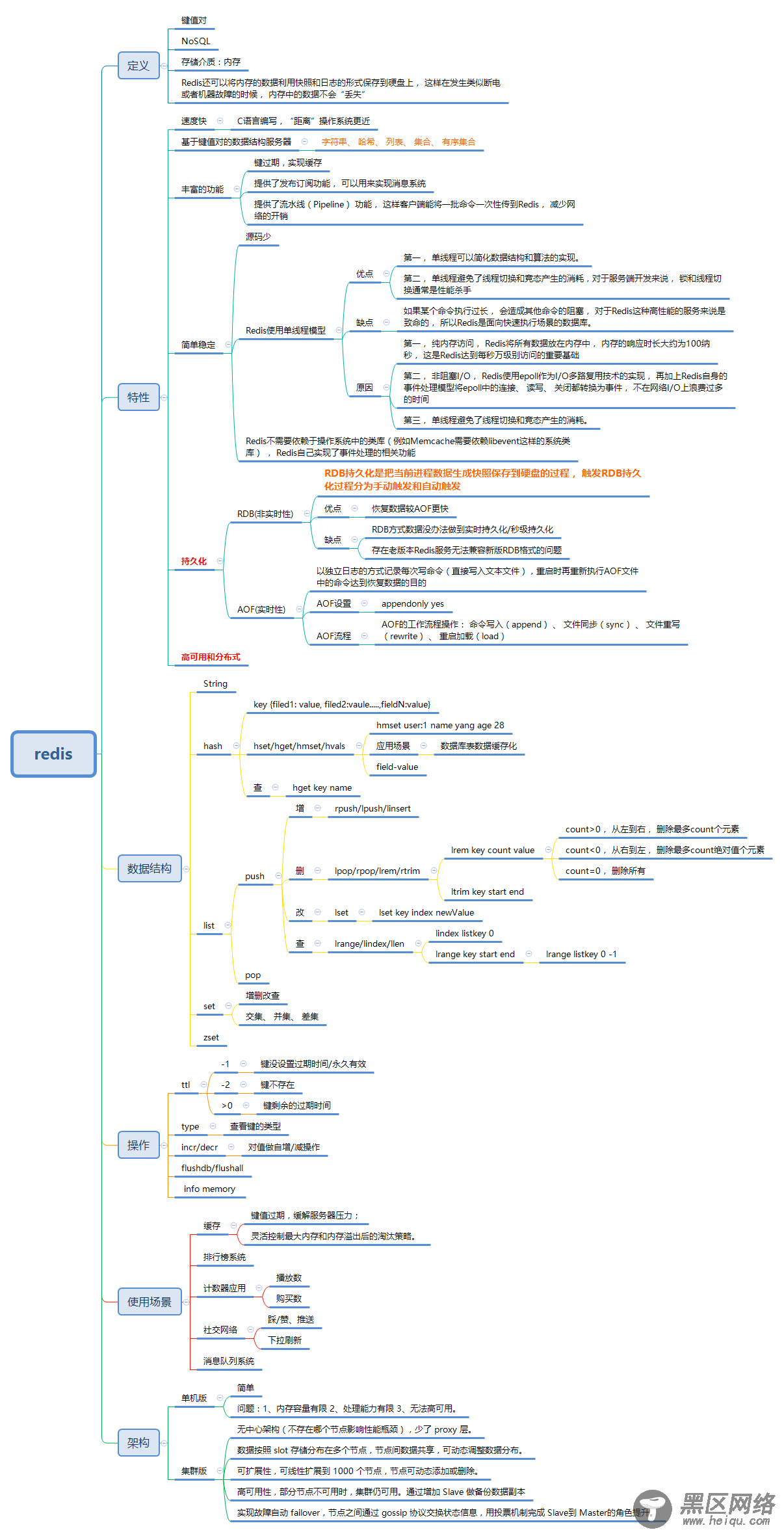
redis思维导图与redis简易操作的Python脚本可以到Linux公社资源站下载:
------------------------------------------分割线------------------------------------------
具体下载目录在 /2018年资料/12月/19日/Redis数���类型与常用操作详解/
------------------------------------------分割线------------------------------------------
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx