
由 proxy 服务器统一调度发送测试请求频率,直接使用 proxy 方案优点是可以兼容之前没做限速功能的扫描器,缺点是所有基于 time based 的检测均无效(当然也可以让 proxy 返回真正的响应时间来进行判断,不过仍需要修改检测模块),也不允许在检测模块中加入超时设置。
双重队列另外一种方法是使用双重队列实现限速功能,流程图如下:
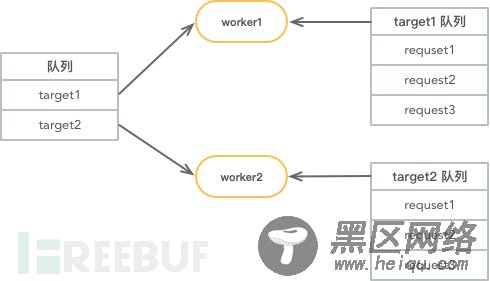
1.worker1 从队列中取到名为 target1 的任务
2.worker1 从 target1 队列中取出和 target1 相关的任务
3.默认单并发执行和 target1 相关任务,根据设置的 QPS 限制,主动 sleep 或者增加并发
这种方案的缺点是扫描器设计之初的时候就得使用这种方法,优点是每个并发可以稳定的和远程服务器保持链接,也不影响扫描功能。
0×05 漏洞检测实际上这一节并不会讲具体某个漏洞检测方法,只是简单谈一下漏扫模块每个阶段该干的事情。
项目之初,没有相关积累,那么可以选择看一下 AWVS 的检测代码,虽然说网上公开的是 10.5 的插件代码,但其实从 8.0 到 11 的插件代码和 10.5 的也差不多,无非新增检测模块,修复误漏报的情况,也可以多看看 SQLMap 代码,看看检测逻辑,但是千万不要学习它的代码风格。从这些代码中可以学习到非常多的小技巧,比如动态页面检测,识别 404 页面等。看代码很容易理解相关的逻辑,但我们需要去理解为什么代码这样处理,历史背景是什么,所以多用 git blame。
到了中期,需要提升漏洞检测的精准度,漏洞检测的精准度是建立在各种 bad case 上,误报的 case 比较容易收集和解决,漏报的 case 就需要其他资源来配合。作为甲方如果有漏洞收集平台,那么可以结合白帽子以及自己部门渗透团队提交的漏洞去优化漏报情况。如果扫描器是自己的一个开源项目的话,那么就必须适当的推广自己的项目,让更多的人去使用、反馈,然后才能继续完善项目,从而继续推广自己的项目,这是一个循环的过程。总而言之,提升漏洞检测的精准度需要两个条件,1. bad case,2. 维护精力。
到了后期,各种常规的漏洞检测模块已经实现完成,也有精力持续提升检测精准度,日常漏洞 PoC 也有人员进行补充。那么事情就结束了么?不,依旧有很多事情我们可以去做,扫描器的主要目标是在不影响业务的情况下,不择手段的发现漏洞,所以除了常规的资产收集方式之外,我们还可以从公司内部各处获取资产相关的数据,比方说从 HIDS 中获取所有的端口数据、系统数据,从流量中或业务方日志中获取 url 相关数据等。当然除了完善资产收集这块,还有辅助提升检测效果的事情,比如说上面提到的 AcuSensor,这部分事情可以结合公司内部的 RASP 做到同样效果,还有分析 access log、数据库 log 等事情。总的来说,做漏扫没有什么条条框框限制,只要能发现漏洞就行。
以上都是和技术相关的事情,做漏扫需要处理的事情也不仅仅只有技术,还需要去搞定详细可操作的漏洞描述及其解决方案,汇报可量化的指标数据,最重要的是拥有有理有据、令人信服的甩锅技巧。