
有台MySQL服务器不定时的会出现并发线程的告警,从记录信息来看,有大量insert的慢查询,执行几十秒,等待flushing log,状态query end
【初步分析】
从等待资源来看,大部分时间消耗在了innodb_log_file阶段,怀疑可能是磁盘问题导致,经过排查没有发现服务器本身存在硬件问题
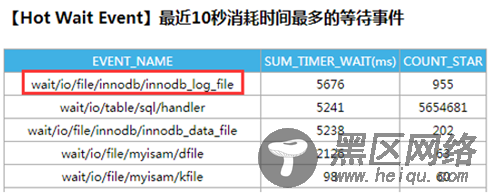
后面开启线程上升时pstack的自动采集,定位MySQL线程等待的位置。
【分析过程】
部署了pstack的自动抓取后,出现过6次thread concurrency >=50的告警(每次告警时会有大量的慢查询产生),有3次抓到了现场。
并发线程升高时,有50多个线程卡在Stage_manager::enroll_for函数,处于group commit阶段
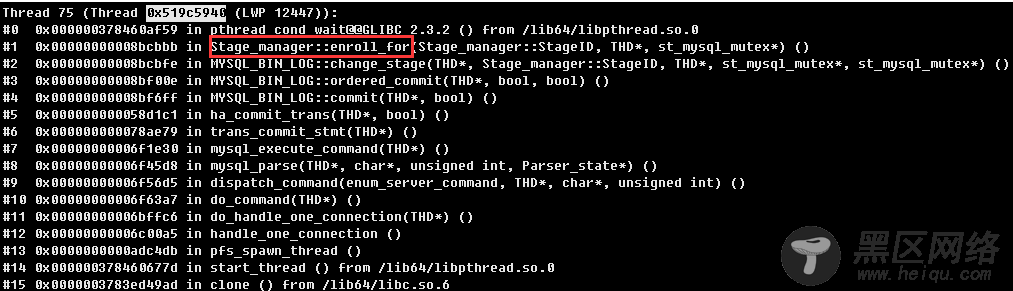
线程0x519c5940对应的SQL语句如下,已经执行18秒
Stage_manager::enroll_for函数的作用实现了多个线程在flush_stage阶段的排队。简单来说,对于一个分组的事务,是被leader线程去提交的,其他线程处于排队等待状态,等待leader线程将该线程的事务提交完成。
如果第一个线程执行慢,后面的线程都处于等待状态,整组事务无法提交。
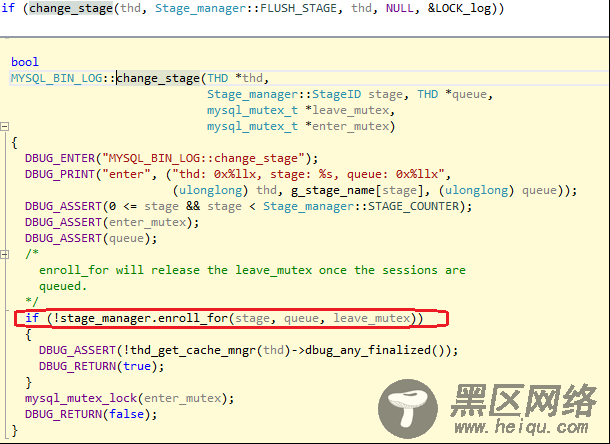
流程也可以理解如下,
Session A COMMIT-->拿到锁-->进行binlog写-->commit完成
Session B COMMIT-->等待锁--------------------------->拿到锁-->进行binlog写-->commit完成
第一个线程为什么执行很慢,分析了发生告警时间段的日志文件,发现日志中存在2个15M和20M的大事务
查看日志明细,存在delete from的大事务删除语句,约包含23W条记录,ROW模式下删除23W条记录,会产生大约20M的日志文件,刷盘时间较长,阻塞了同一个分组下其他事务的提交。
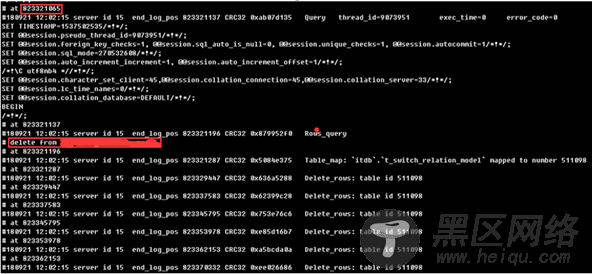
事务的开始时间与告警时间吻合
积压的分组下事务集中刷盘,反应到磁盘指标上可以看到在问题时间段的disk_write_kbytes指标出现明显的上升
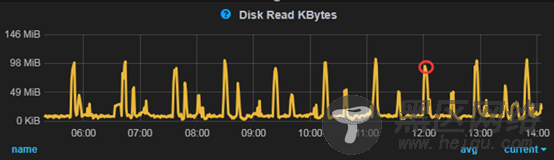
【优化方案】
1、 建议开发避免使用delete from 整表的大事务删除语句
【其他变通方案】
2、 Binlog 记录的ROW模式下会产生大量的日志,改为MIXED模式,理论上也可以解决问题
3、 更换性能好的磁盘
Linux公社的RSS地址:https://www.linuxidc.com/rssFeed.aspx