
随着MySQL MGR的版本的升级以及技术成熟,在把MHA拉下神坛之后, MGR越来越成为MySQL高可用的首选方案。
MGR的搭建并不算很复杂,但是有一系列手工操作步骤,为了简便MGR的搭建和故障诊断,这里完成了一个自动化的脚本,来实现MGR的自动化搭建,自动化故障诊断以及修复。
MGR自动化搭建
为了简便起见,这里以单机多实例的模式进行测试,
先装好三个MySQL实例,端口号分别是7001,7002,7003,其中7001作为写节点,其余两个节点作为读节,8000节点是笔者的另外一个测试节点,请忽略。
在指明主从节点的情况下,如下为mgr_tool.py一键搭建MGR集群的测试demo
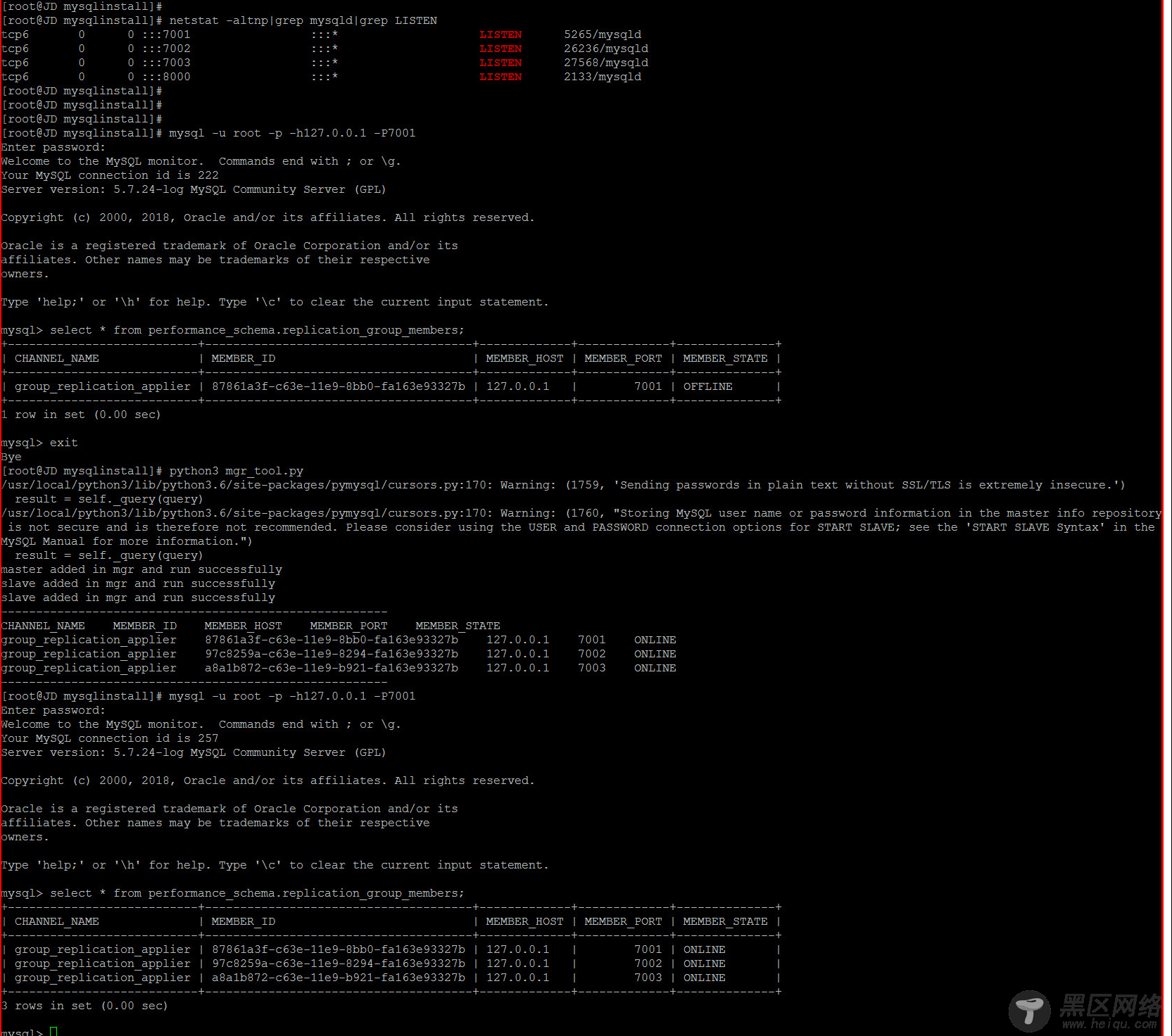
MGR故障模拟1
MGR节点故障自动监测和自愈实现,如下是搭建完成后的MGR集群,目前集群处于完全正常的状态中。
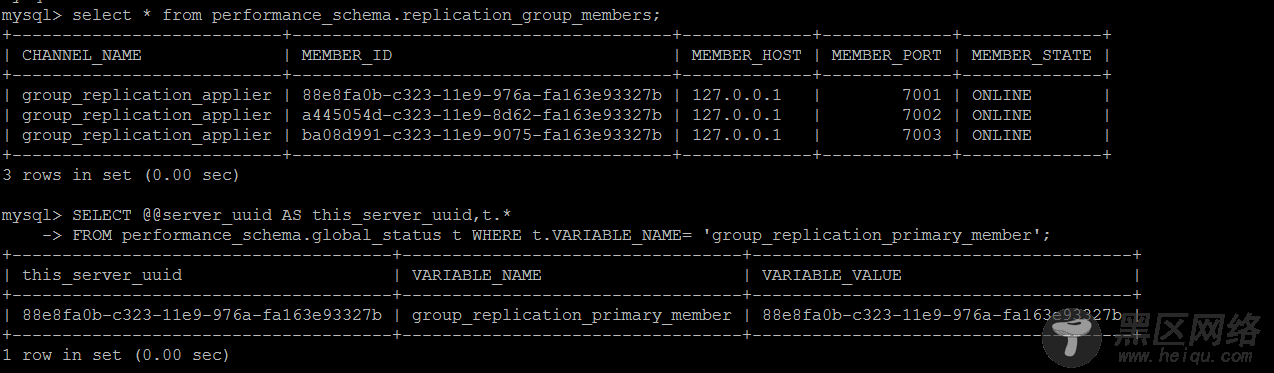
主观造成主从节点间binlog的丢失

在主节点上对于对于从节点丢失的数据操作,GTID无法找到对应的数据,组复制立马熄火
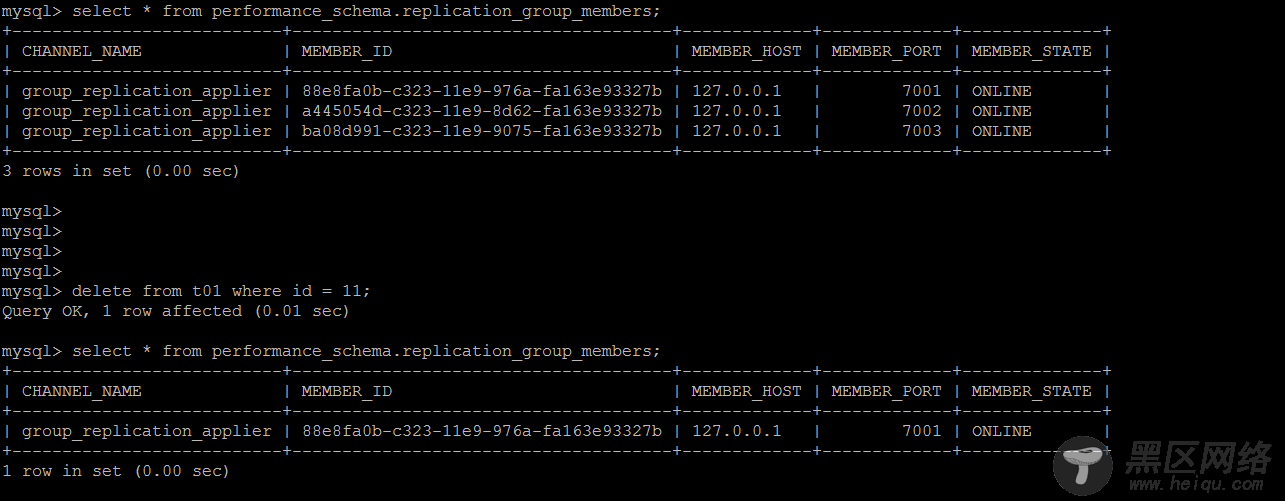
非写入节点出现错误
看下errorlog
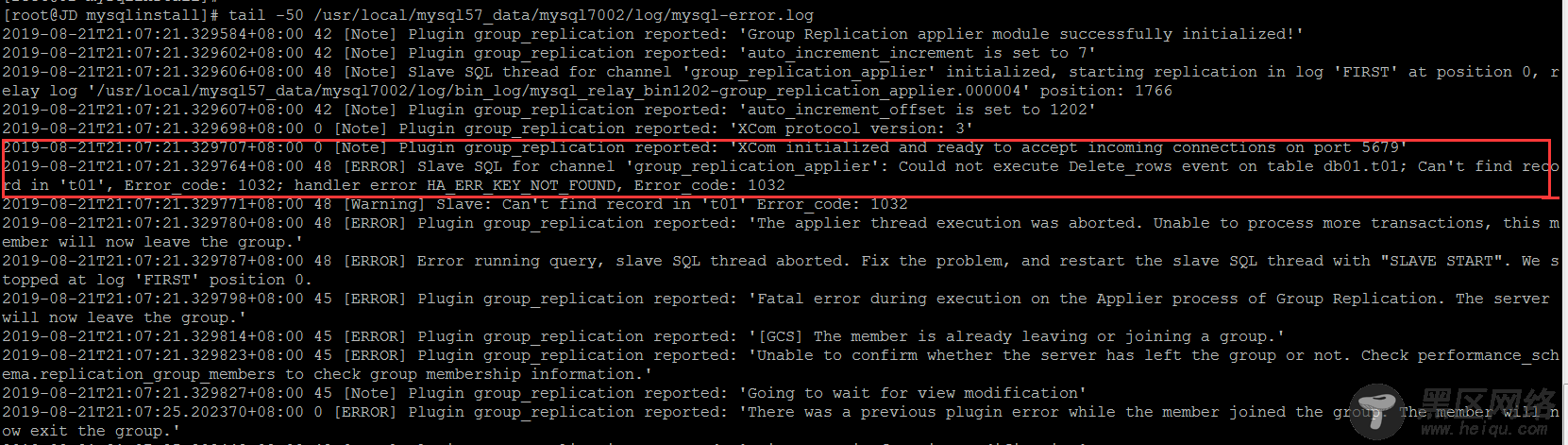
如果是手动解决的话,还是GTID跳过错误事物的套路,master上的GTID信息

尝试跳过最新的一个事物ID,然后重新连接到组,可以正常连接到组,另外一个节点仍旧处于error状态
stop group_replication;
SET GTID_NEXT='6c81c118-e67c-4416-9cb0-2d573d178c1d:13';
BEGIN; COMMIT;
set gtid_next='automatic';
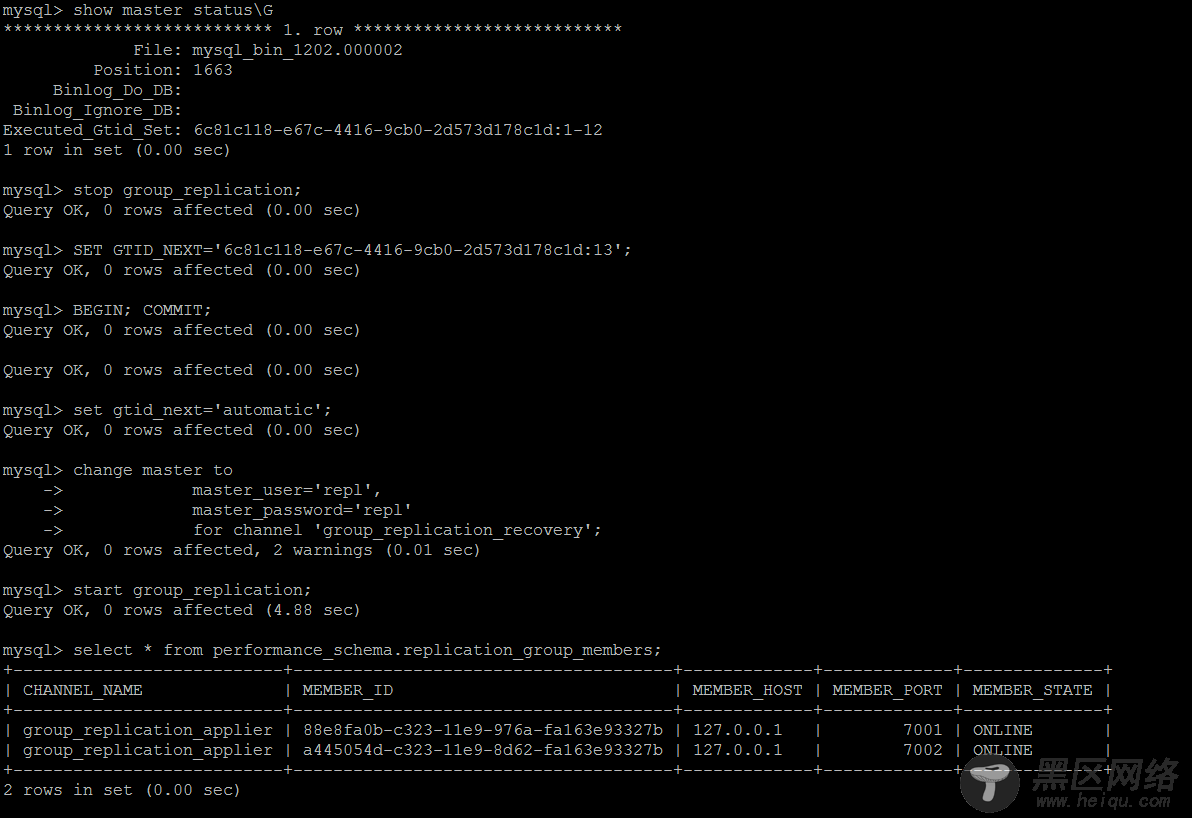
另外一个节点类似,依次解决。
MGR故障模拟2
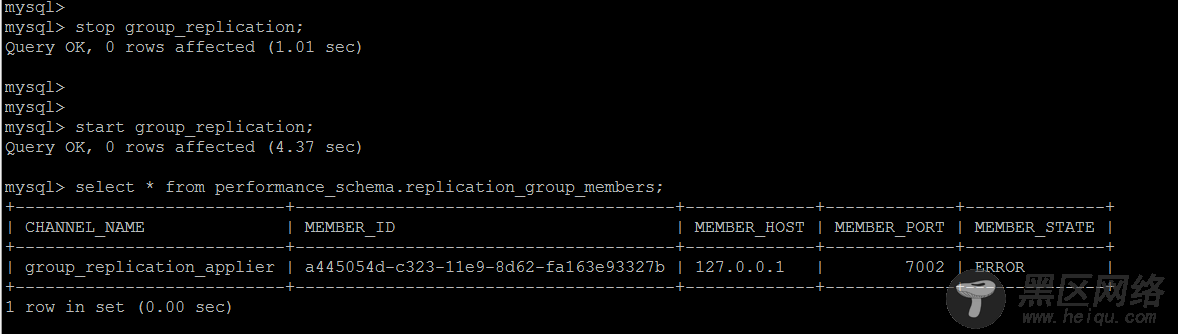
从节点脱离Group
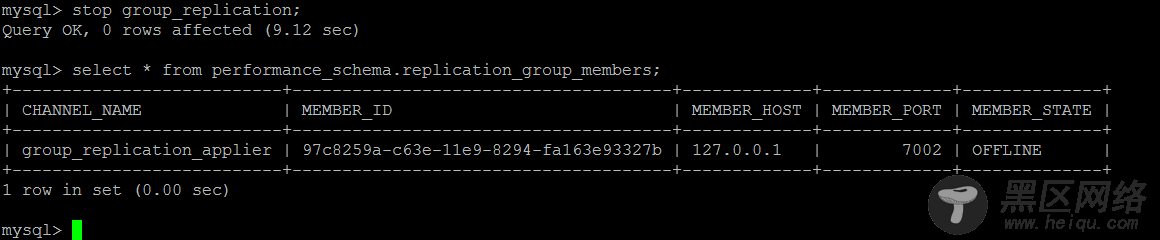
这种情况倒是比较简单,重新开始组复制即可,start group_replication
MGR故障自动检测和修复
对于如上的两种情况,
1,如果是从节点丢失主节点的事物,尝试在从节点上跳过GTID,重新开始复制即可
2,如果是从节点非丢失主节点事物,尝试在从节点重新开始组复制即可
实现代码如下
def auto_fix_mgr_error(conn_master_dict,conn_slave_dict): group_replication_status = get_group_replication_status(conn_slave_dict) if(group_replication_status[0]["MEMBER_STATE"]=="ERROR" or group_replication_status[0]["MEMBER_STATE"] == "OFFLINE"): print(conn_slave_dict["host"]+str(conn_slave_dict["port"])+'------>'+group_replication_status[0]["MEMBER_STATE"]) print("auto fixing......") while 1 > 0: master_gtid_list = get_gtid(conn_master_dict) slave_gtid_list = get_gtid(conn_slave_dict) master_executed_gtid_value = int((master_gtid_list[-1]["Executed_Gtid_Set"]).split("-")[-1]) slave_executed_gtid_value = int(slave_gtid_list[-1]["Executed_Gtid_Set"].split("-")[-1]) slave_executed_gtid_prefix = slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[0] slave_executed_skiped_gtid = slave_executed_gtid_value + 1 if (master_executed_gtid_value > slave_executed_gtid_value): print("skip gtid and restart group replication,skiped gtid is " + slave_gtid_list[-1]["Executed_Gtid_Set"].split(":")[-1].split("-")[0] + ":"+str(slave_executed_skiped_gtid)) slave_executed_skiped_gtid = slave_executed_gtid_prefix+":"+str(slave_executed_skiped_gtid) skip_gtid_on_slave(conn_slave_dict,slave_executed_skiped_gtid) time.sleep(10) start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break else: start_group_replication(conn_slave_dict) if(get_group_replication_status(conn_slave_dict)[0]["MEMBER_STATE"]=="ONLINE"): print("mgr cluster fixed,back to normal") break elif (group_replication_status[0]['MEMBER_STATE'] == 'ONLINE'): print("mgr cluster is normal,nothing to do") check_replication_group_members(conn_slave_dict)
对于故障类型1,GTID事物不一致的自动化修复
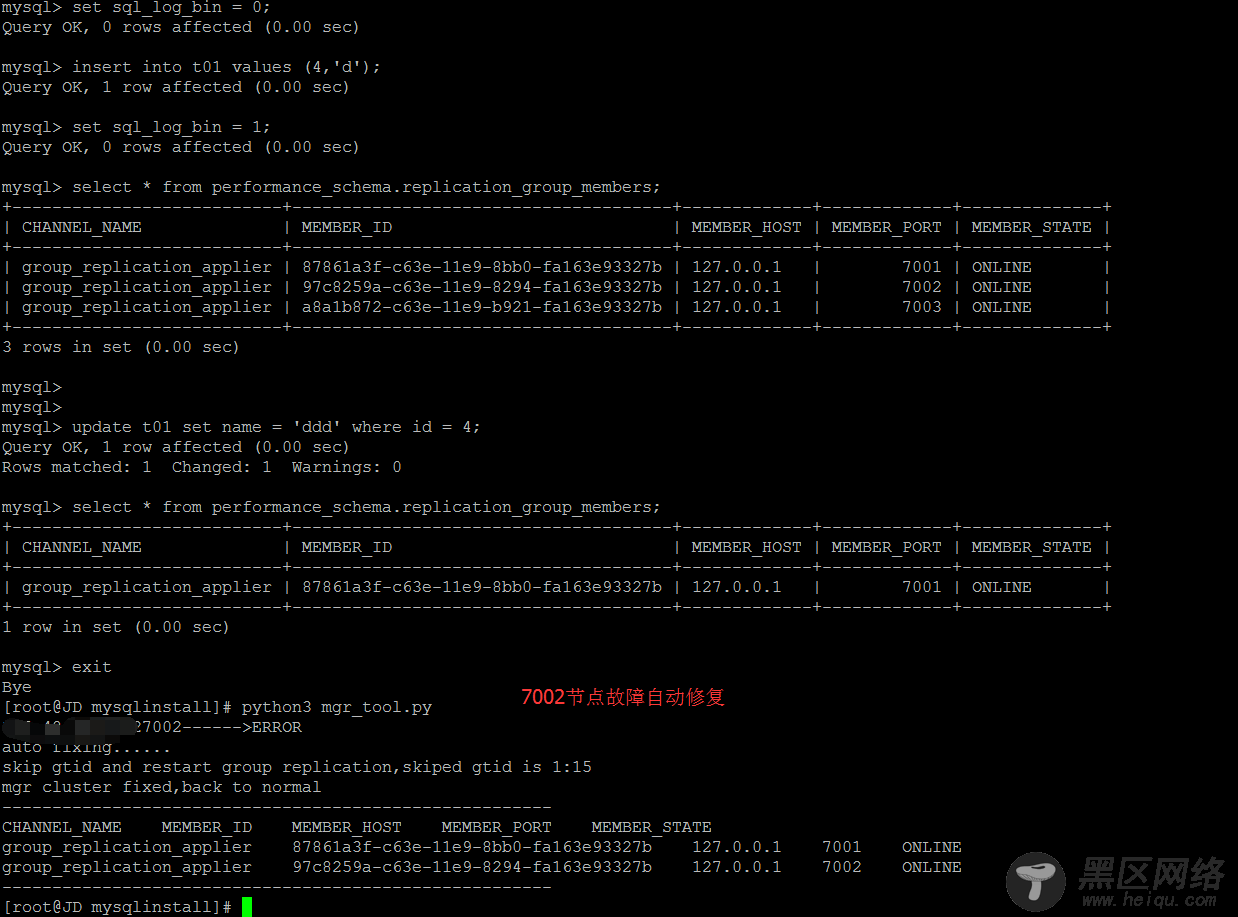
对于故障类型2从节点offline的自动化修复
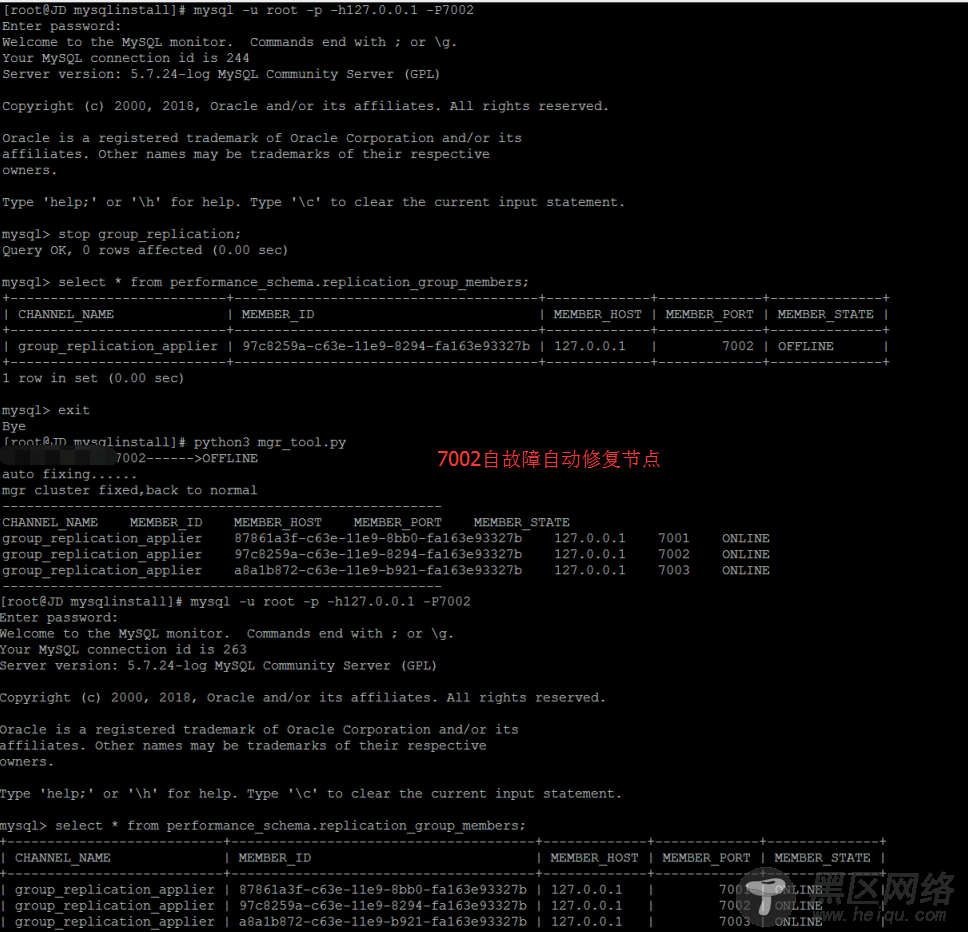
完整的实现代码
该过程要求MySQL实例必须满足MGR的基本条件,如果环境本身无法满足MGR,一切都无从谈起,因此要非常清楚MGR环境的最基本要求