
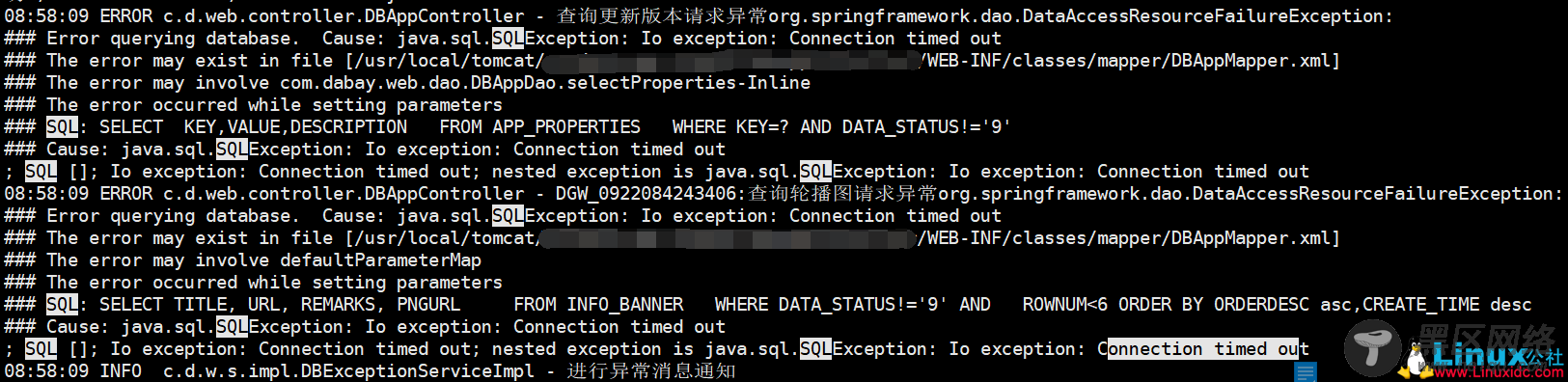
1,给同事安装了一个生产Oracle数据库,最近一段时间 总是在2点-10点之间出现数据库连不上的情况,具体tomcat应用日志如下:
08:58:09 ERROR c.d.web.controller.DBAppController - 查询更新版本请求异常org.springframework.dao.DataAccessResourceFailureException:
### Error querying database. Cause: java.sql.SQLException: Io exception: Connection timed out
### The error may exist in file [/usr/local/tomcat/xx/WEB-INF/classes/mapper/DBAppMapper.xml]
### The error may involve com.dabay.web.dao.DBAppDao.selectProperties-Inline
### The error occurred while setting parameters
### SQL: SELECT KEY,VALUE,DESCRIPTION FROM APP_PROPERTIES WHERE KEY=? AND DATA_STATUS!='9'
### Cause: java.sql.SQLException: Io exception: Connection timed out
; SQL []; Io exception: Connection timed out; nested exception is java.sql.SQLException: Io exception: Connection timed out
08:58:09 ERROR c.d.web.controller.DBAppController - DGW_0922084243406:查询轮播图请求异常org.springframework.dao.DataAccessResourceFailureException:
### Error querying database. Cause: java.sql.SQLException: Io exception: Connection timed out
### The error may exist in file [/usr/local/tomcat/xx/WEB-INF/classes/mapper/DBAppMapper.xml]
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: SELECT TITLE, URL, REMARKS, PNGURL FROM INFO_BANNER WHERE DATA_STATUS!='9' AND ROWNUM<6 ORDER BY ORDERDESC asc,CREATE_TIME desc
### Cause: java.sql.SQLException: Io exception: Connection timed out
; SQL []; Io exception: Connection timed out; nested exception is java.sql.SQLException: Io exception: Connection timed out
2,想到排查ORACLE数据库是否正常,百度到了如下三个结果
一:查看数据库监听是否启动
lsnrctl status
二:查看数据库运行状态,是否open
select instance_name,status from v$instance;
三:查看alert日志,查看是否有错误信息
SQL> show parameter background_dump
NAME TYPE
------------------------------------ ----------------------
VALUE
------------------------------
background_dump_dest string
/u01/app/oracle/diag/rdbms/just_test/test/trace
是的,有alert日志,接下来查看alert日志,如下
db_recovery_file_dest_size of 3882 MB is 45.88% used. This is a
user-specified limit on the amount of space that will be used by this
database for recovery-related files, and does not reflect the amount of
space available in the underlying filesystem or ASM diskgroup.
Fri Sep 22 02:01:05 2017
Starting background process CJQ0
Fri Sep 22 02:01:05 2017
CJQ0 started with pid=22, OS id=6797
Fri Sep 22 02:06:05 2017
Starting background process SMCO
Fri Sep 22 02:06:05 2017
SMCO started with pid=32, OS id=7393
Fri Sep 22 04:21:10 2017
Thread 1 cannot allocate new log, sequence 221
Private strand flush not complete
Current log# 1 seq# 220 mem# 0: /u01/app/oracle/oradata/hsrs_pro/redo01.log
Thread 1 advanced to log sequence 221 (LGWR switch)
Current log# 2 seq# 221 mem# 0: /u01/app/oracle/oradata/hsrs_pro/redo02.log
Fri Sep 22 09:00:35 2017
先看到了 Thread 1 cannot allocate new log, sequence 221,于是又百度了一下,找到了如下结果
这个实际上是个比较常见的错误。通常来说是因为在日志被写满时会切换 日志组,这个时候会触发一次checkpoint,DBWR会把内存中的脏块往数据文件中写,只要没写结束就不会释放这个日志组。如果归档模式被开启的 话,还会伴随着ARCH写归档的过程。如果redo log产生的过快,当CPK或归档还没完成,LGWR已经把其余的日志组写满,又要往当前的日志组里面写redo log的时候,这个时候就会发生冲突,数据库就会被挂起。并且一直会往alert.log中写类似上面的错误信息。
于是有了以下的操作:
SQL> select group#,sequence#,bytes,members,status from v$log; #查看每组日志的状态
GROUP# SEQUENCE# BYTES MEMBERS STATUS
---------- ---------- ---------- ---------- --------------------------------
1 220 52428800 1 INACTIVE ##空闲的
2 221 52428800 1 CURRENT ##当前的
3 219 52428800 1 INACTIVE ##空闲的
SQL> alter database add logfile group 4 ('/u01/app/oracle/oradata/xx/redo04.log') size 500M; 增加日志组
Database altered.
SQL> alter database add logfile group 5 ('/u01/app/oracle/oradata/xx/redo05.log') size 500M;
Database altered.
SQL> alter system switch logfile; 切换日志组