
公司Hadoop集群从1.2.1升级到2.2.0已经有一段时间,这篇blog将总结一下我前段时间在升级至Hadoop2.2.0版本过程中遇到的一些问题,以及具体的升级步骤。
二、升级过程
(1)停掉hadoop1.x集群。
(2)备份namenode原数据,即备份dfs.namenode.name.dir指向的路径。以免造成由于升级版本带来的风险。
(3)下载hadoop-2.2.0解压,用scp将解压后的hadoop-2.2.0复制到各个子节点。修改各个子节点的hadoop用户的配置文件,如果是ubumtu这编辑~/.bash_profile文件,将$HADOOP_HOME指向新版 本hadoop-2.2.0,以及更新相应的环境变量。
(4)将Hadoop2.2.0的${HADOOP_HOMOE}/etc/hadoop/hdfs-site.xml中dfs.namenode.name.dir和dfs.datanode.data.di属性的值分别指向hadoop1.x的${HADOOP_HOME}/conf/hdfs-site.xml中dfs.name.dir和dfs.data.dir的值。
(5)启动相关进程。
启动namenode,直接执行启动命令:$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode会被提示版本不一致,这个时候就可以直接采用upgrade方式启动namenode:$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode -upgrade 执行命令过后,如果你集群之前升级过,而且没有最经commit,那么就会残留有之前版本的信息,看dfs.namenode.name.dir路径信息存在previous.checkpoint文件夹:
这个时候你upgrade是会出错的,错误信息如下:
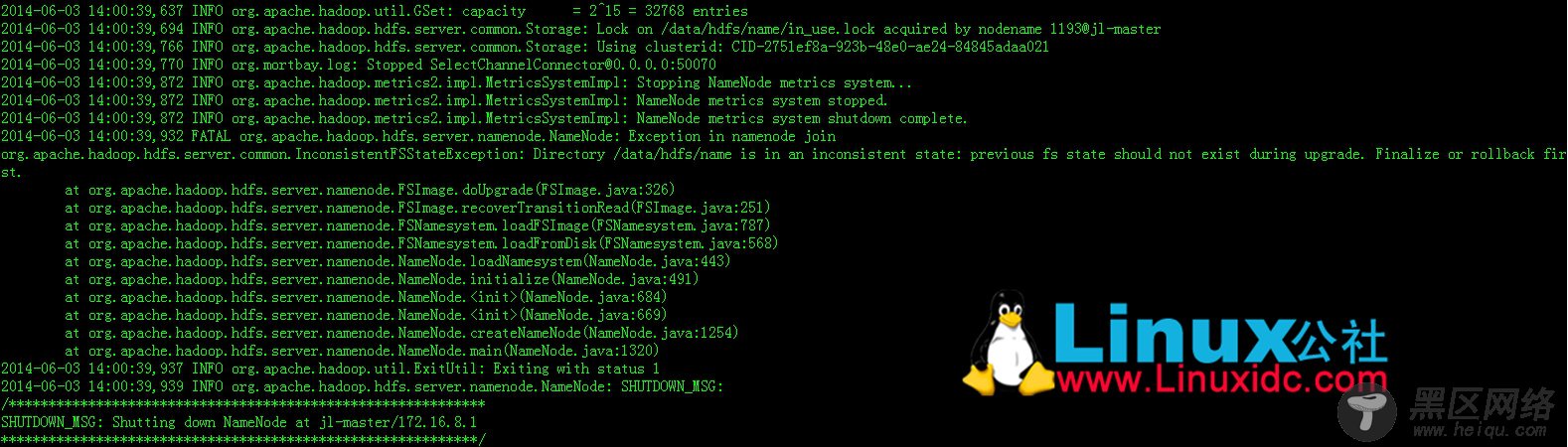
要想升级成功必须将你之前升级过程中的版本信息删除掉,这里执行$HADOOP_HOME/bin/hdfs dfsadmin -finalizeUpgrade之前的版本信息就会被删掉,但是删掉以后你不能rollback回到之前的版本。这样删除旧版信息后,就可以$HADOOP_HOME/sbin/hadoop-daemon.sh start namenode -upgrade进行升级了。当升级完成之后,又会生成一个旧版办备份信息,存在在dfs.namenode.name.dir路径中的previous.checkpoint文件夹中,用于之后的版本rollback操作。
(6)Hadoop2.2.0升级到这里已经完毕并且namenode进程已经启动。现在将其他进程启动起来,依次启动ResourceManager、WebAppProxyServer、JobHistoryServer、启动各个slave节点的nodeManager和datanode进程。这个要主要两个进程的,一个是JobHistoryServer,这个进程主要是保存和处理作业的日志信息,这个进程必须启动,不然看不到job的日志信息。另外,WebAppProxyServer这个进程主要作用是作为HADOOP web页面的一个代理,主要是为了安全考虑,也一定要启动。
另外,关于Hadoop2.x的JournalNodes、active NN和standby NN等HA方式,及如何部署和各自的原理,请看:
--------------------------------------分割线 --------------------------------------
Ubuntu 13.04上搭建Hadoop环境
Ubuntu 12.10 +Hadoop 1.2.1版本集群配置
Hadoop: The Definitive Guide【PDF版】
--------------------------------------分割线 --------------------------------------